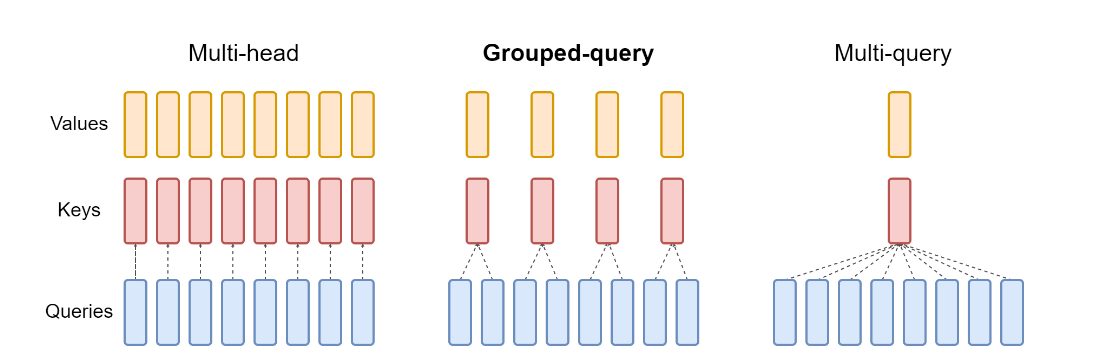
KV Cache(二):从如何让GPU不摸鱼开始思考——MQA、GQA到MLA的计算拆解
1 前言 这是 KV Cache 系列的第二篇,接着上一篇[[KV Cache(一):从KV Cache看懂Attention(MHA、MQA、GQA、MLA)的优化]]继续往下走。 这篇确确实实写的比较长,涵盖了 MQA/GQA 的拆解计算和 MLA 的完整推导。本来想着用例子讲的细一点,没想到这...
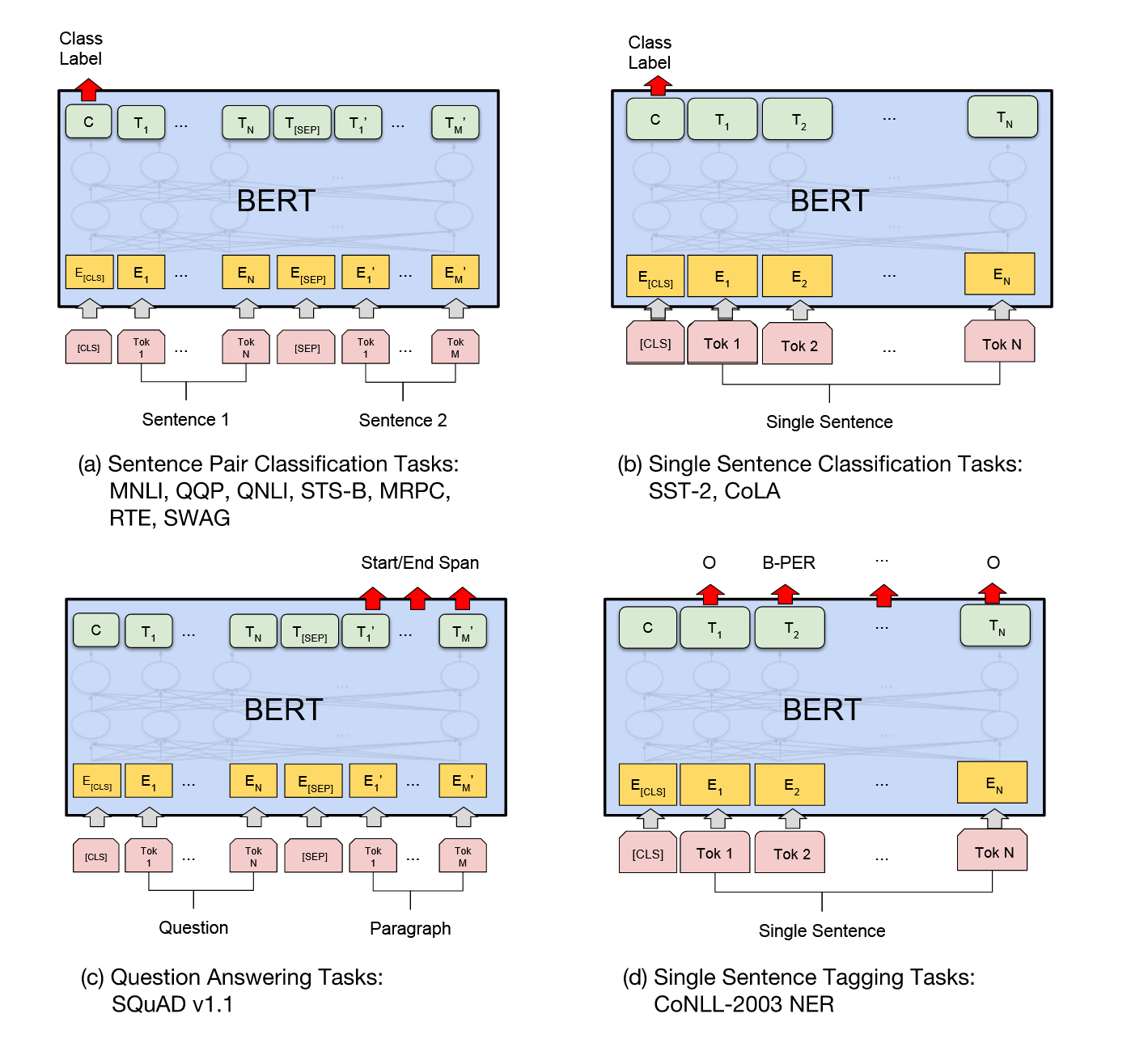
通过下游任务理解BERT和GPT的区别:不只是完形填空和词语接龙
1 写在前面 好久没更新,非常对不住打赏的佬们。本来想写一个大一点的内容,不过还是低估了内容的丰富和复杂度,一直在修修改改。先开个小坑过渡一下吧。 2 TL;DR 很多人接触AI,都是直接从GPT开始的。对于一些传统的模型任务和理解不够深入,所以这次要从从最初要解决的任务出发,经过下游任务设计、预训...
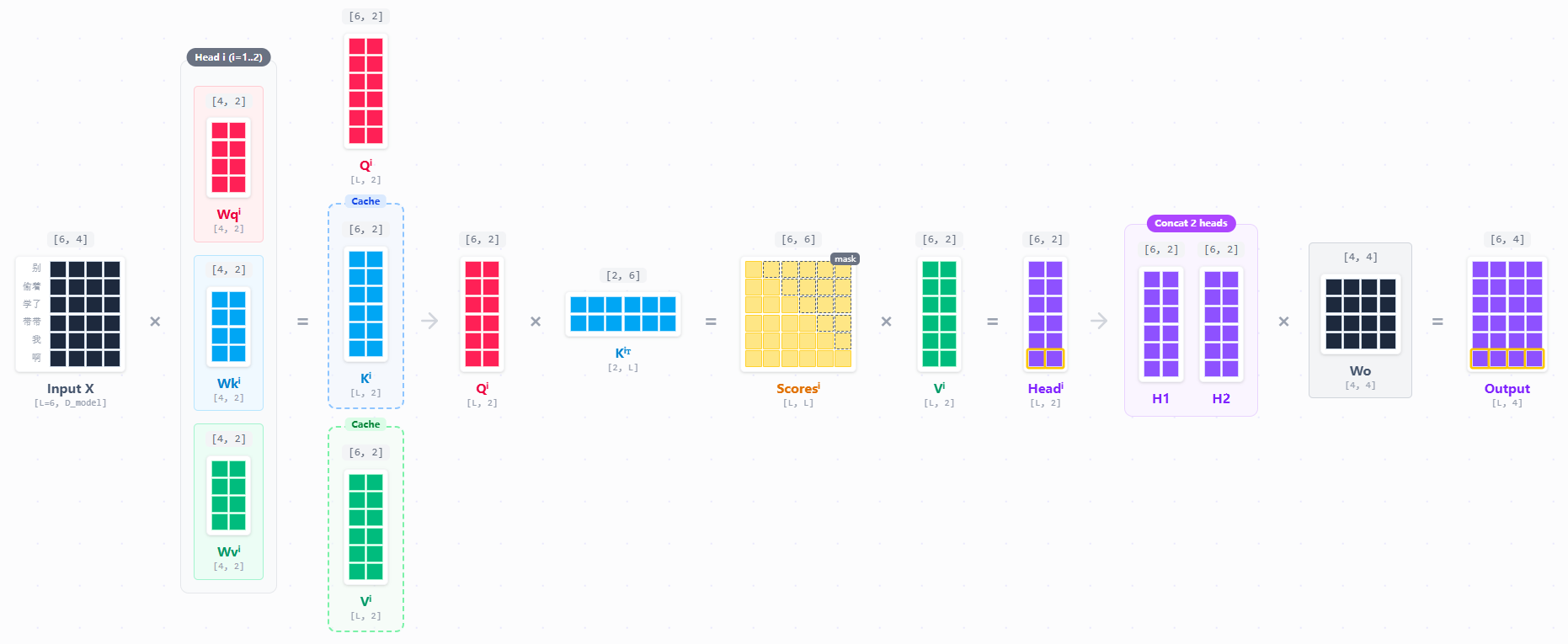
KV Cache(一):从KV Cache看懂Attention(MHA、MQA、GQA、MLA)的优化之路
1 TL;DR 本文的目标在于理清楚一个核心问题:为什么主流llm纷纷从传统的多头注意力转向了MQA、GQA、MLA等变体? 关键在于解码阶段的 KV Cache 及其引发的 “内存墙” 问题。内容如下: 1. Prefill 与 Decoding 两阶段的本质区别。 2. KV Cache 如何以...
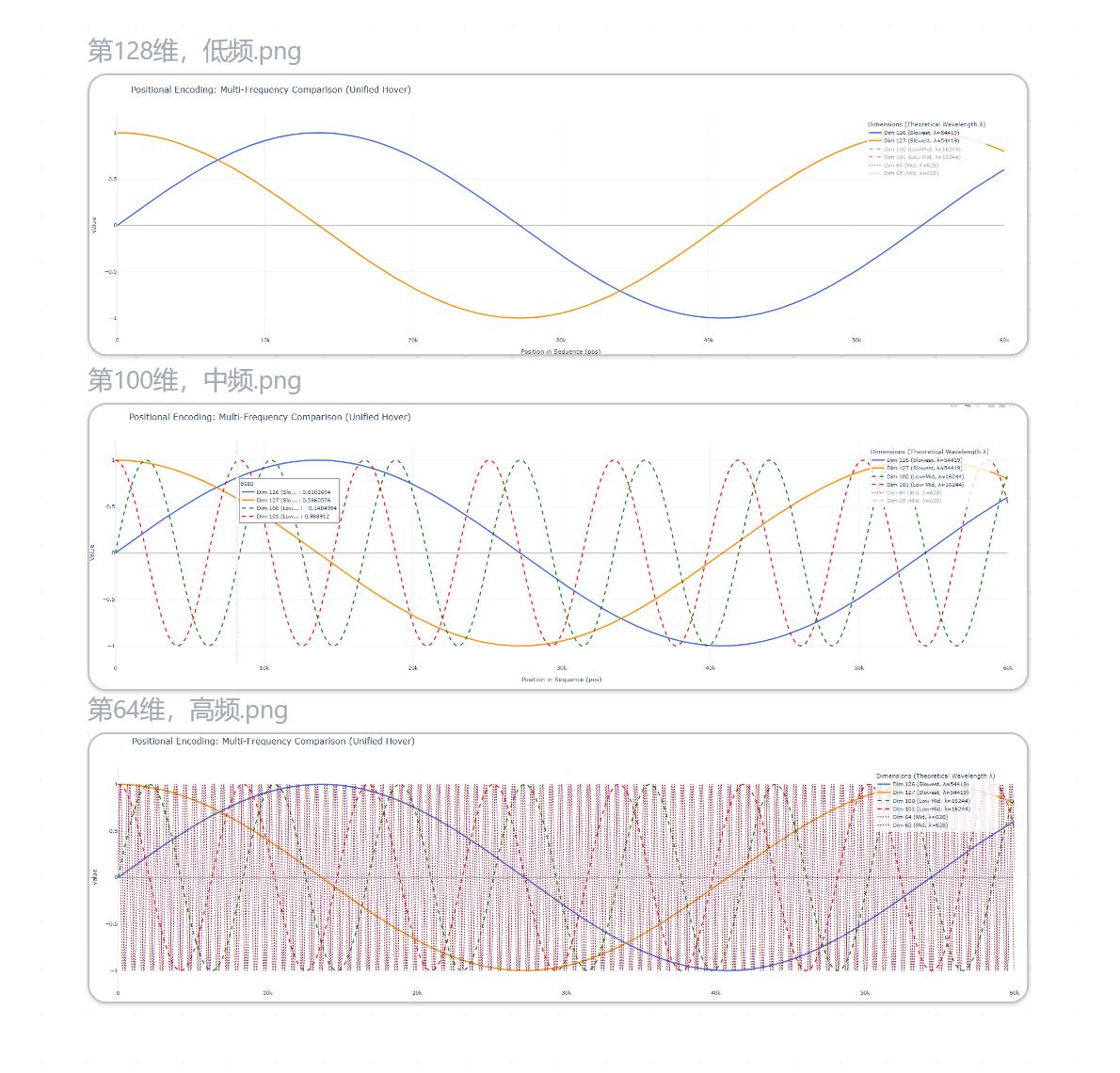
为什么Embedding加上位置编码后不会破坏语义?
通过位置编码的加法操作分析正余弦编码的推导逻辑以及高维空间特点
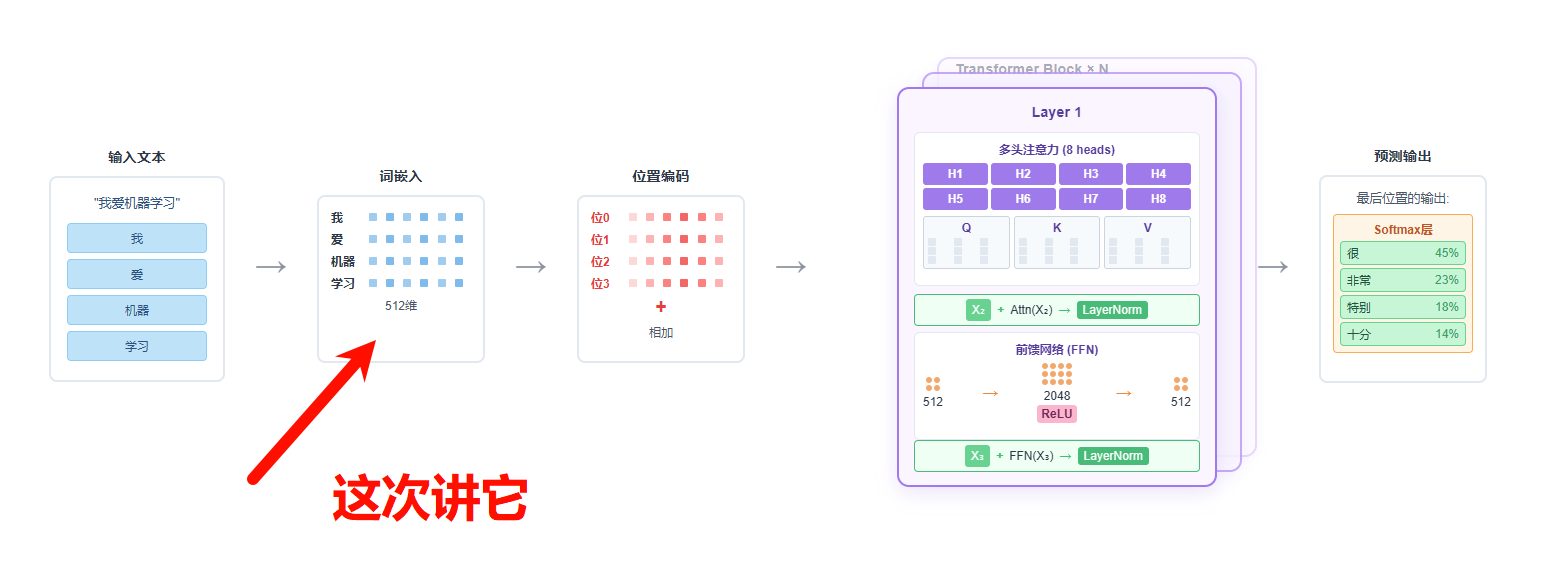
流形视角下的Embedding:从理论到RAG实践
1 TL,DR; 把embedding放在基础原理靠后的地方,其实是我写这个系列一开始就想好的。毕竟有了其他模块的一些前置知识以后,可能才会对这些抽象、晦涩的东西感兴趣。 在这部分,我会说一下embedding的的概念,通过流形(Manifold)去从理论角度理解embedding layer,再通...
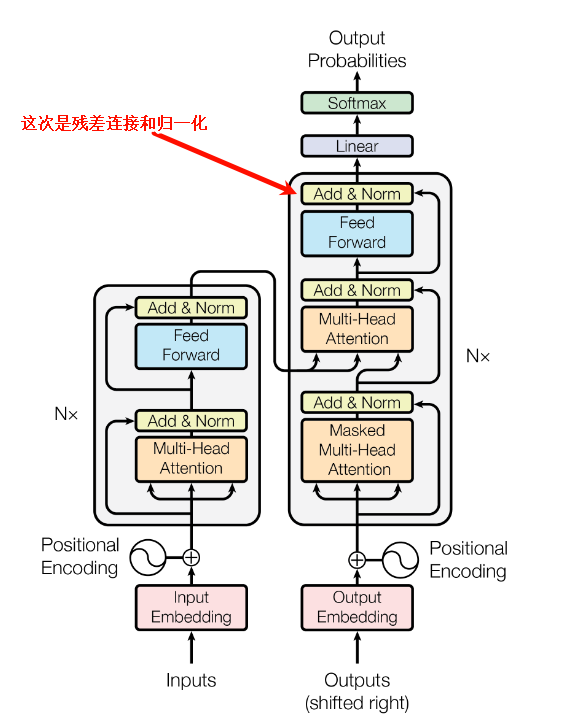
Add & Norm:对残差连接深入解析(一)
写在前面 在我最早学习LLMs时候,残差连接这个词看着就很高大上,让我望而生畏,极大的延缓了我系统的学习的进度。但是,因为这样那样的原因,最终我还是恶补了各种知识。学完之后觉得也就那样了,所以,我希望初学者看到transformer里藏着这样一个部分的时候,可以不用过多担心,直接开始看。 Add &...