1 引言
领导看了几篇营销号推文,突然要求在有限的算力上部署和微调大模型。当你开始研究,却发现眼前摆着一堆框架和工具,你好不容易理清楚了发现无从下手:
- 训练框架:accelerate、deepspeed、llamafactory、megatron、unsloth...
- 部署方案:vllm、ollama、sglang...
- 官方工具:transformers、trl、peft...
WTF!果然人和代码必须跑一个!
网上很多例子都是通过命令行传参,实际工作中也这样的方式也更方便修改参数。但是作为教程,不太方便我的单线程大脑去直观理解。所以这次通过硬编码的方式,按照逻辑流程一步步实现训练代码。
另外,我不想从SFT去说,网上很多教程都是在说SFT。但是当我第一次跟着训练以后,我会觉得两个答案都挺好啊。所以为了更直观的体现训练结果,我们直接DPO。
2 学习路线
2.1 第一部分:最小化实现
- 环境准备
- 模型加载
- LoRA配置
- 数据集处理
- 训练参数设置
- 执行训练
2.2 第二部分:高级配置
- wandb可视化监控
- 模型量化配置
2.3 第三部分:分布式训练配置
- DP vs DDP vs FSDP
- accelerate
- deepspeed
3 准备工作
在开始之前,请确保:
WARNING
开始之前请务必确认你的nvidia-driver和cuda版本还有python里的torch都是对应的。
第一件事:用nvidia-smi确认你driver版本  image.png
image.png
第二件事:用nvcc --version确认你的cuda版本 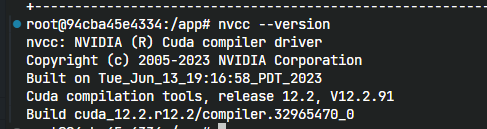 image.png
image.png
第三件事:确认你的pytorch版本 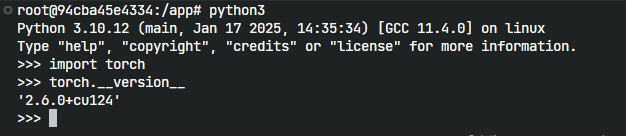 image.png
image.png
最后,我们确认其他环境
基础环境要求:
- Python 3.10+(不是必要,但是我们还是尽量不用太低版本的python)
- CUDA 11.8+
- 12G显存(越高越好,你可以尝试更高参数量的模型)
需要安装的主要包:
- transformer
- trl
- peft
- wandb
- torch
- BitsAndBytesConfig
- accelerate
- deepspeed
模型和数据集
- 模型我们用的:
Qwen/Qwen2.5-1.5B-Instruct一个足够小的模型来走通流程 你可以根据自己的显存大小选合适模型,但这次别选量化的模型,因为我们后面要在非量化基础上实现QLoRA - 数据集:
phimes/DPO-bad-boy-chinese-for-Qwen2.5-extended这是一个暴躁的数据集,具体内容上huggingface看吧。后续会基于前人们的基础上,不断扩展。
- 模型我们用的:
4 最小化训练
在开始复杂的分布式训练之前,我们先通过一个精简版实现来理解整个训练流程。本节将帮助你:
- 理解DPO训练的基本组件
- 完成一次完整的训练周期
- 为后续高级特性打下基础
4.1 库导入
4.1.1 代码
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
from peft import LoraConfig, get_peft_model
from trl import DPOTrainer, DPOConfig
from datasets import Dataset, load_dataset4.1.2 代码解释
transformers的AutoModelForCausalLM和AutoTokenizer用于加载模型和tokenizerpeft是huggingface出的微调框架,这里我们用LoRA方法,所以要有它的配置和模型加载方法trl是huggingface出的训练框架,这次我们用DPO训练,所以要有DPO的Trainer模块和DPO配置模块DPOConfig。这里也是我们参数主要配置的地方。dataset用于加载huggingface的数据集。
运行以后出现,不用管它。说明我们之后可以用accelerate,这是好事。
[INFO] [real_accelerator.py:222:get_accelerator] Setting ds_accelerator to cuda (auto detect)4.2 模型加载
4.2.1 代码
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)4.2.2 代码解释
- 用户/组织名称:Qwen
- 模型名称:Qwen2.5-1.5B-Instruct
使用AutoModelForCausalLM加载后,会下载到本地(Linux)路径的~/.cache/huggingface/hub/models--Qwen--Qwen2.5-1.5B-Instruct/下。如果没有下载过就会开始下载,如果下载了他也会先联网检查。
- 如果你有网,可以设置,避免没有梯子的时候无法检查而无法运行HF_ENDPOINThf-mirror.com
- 如果你没网,那么我们可以通过local_files_only参数。
4.3 LoRA配置
微调的方式,我们基于LoRA(Low-Rank Adaptation),LoRA(低秩适应)通过 低秩矩阵分解 重构权重更新量(
其中,
抛开繁杂的公式,其主要作用就是通过仅训练一部分低秩矩阵让极低的参数量可以逼近全量微调。 我们可以通过peft已实现了这个功能,我们直接用即可。
4.3.1 代码
# LoRA配置
LoraConfig = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
task_type="CAUSAL_LM",
)
# 模型应用LoRA配置
model = get_peft_model(model, LoraConfig)4.3.2 代码解释
r: LoRA的秩,常见是4、8、16、32。r决定了低秩矩阵的维度上限。那么维度越高,意味着可训练的参数就越多,但是并不适宜设置过高,一方面是可能会增加计算成本,另一个重要的因为是会增加过拟合的风险, 所以实际任务,还要根据你的资源,和任务类型去尝试不同的r。
lora_alpha: 缩放参数,是用来控制LoRA更新。较大的lora_alpha可以有更大幅度的更新任务。但是也可能过拟合。
target_modules: LoRA的模块名称。想要知道每个模型有什么,也很简单。直接打印模型就能看到。也许你看不懂模型结构,不知道怎么选择。那我们至少先放上
q_proj和v_proj,这是注意力层中的Q和V矩阵的投影。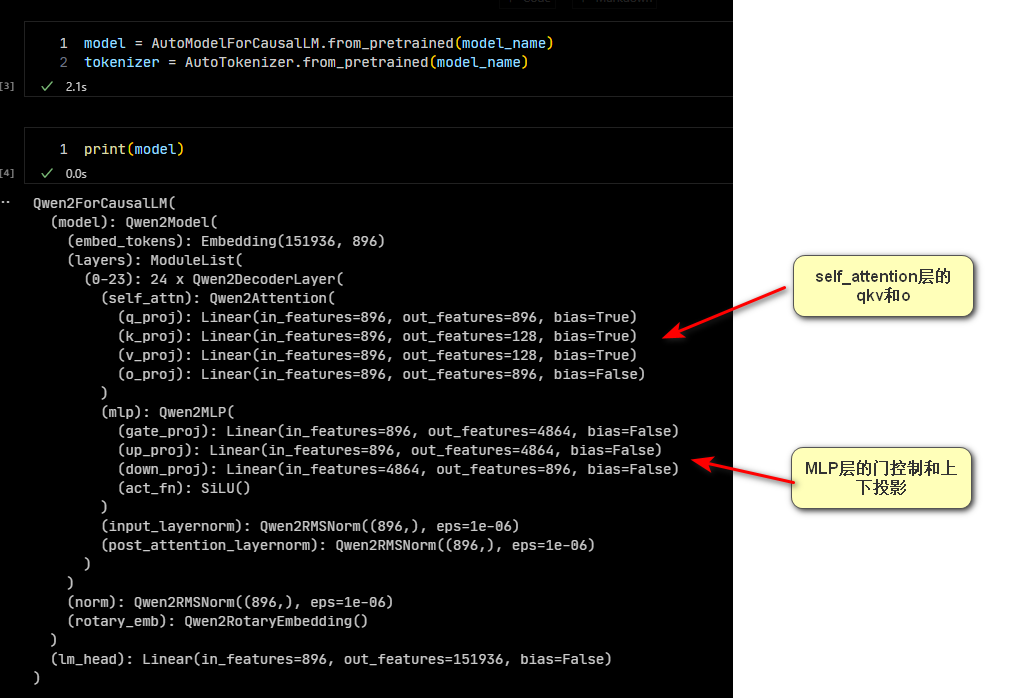 image.png
image.pnglora_dropout: 作用于 LoRA 分支的中间激活值,通过随机丢弃部分输出来防止过拟合。按照不同规模的数据集和任务来设置。一般来说小的数据集为0.1,高秩㐉(r>=16)或者一些复杂任务的情况,可以设置为0.2-0.3
task_type:
- CAUSAL_LM,在一般的大模型训练中我们不会改它,大模型本身是单项注意力机制的预测,所以都使用因果语言模型。
- SEQ_2_SEQ_LM:T5、BART 等编解码结构,适用于需区分输入输出的任务(如翻译)
- SEQ_CLS:文本分类等任务。
4.4 数据集加载
4.4.1 代码
dataset = load_dataset("phimes/DPO-bad-boy-chinese-for-Qwen2.5-extended")
train_dataset = dataset["train"]
test_dataset = dataset["test"]加载的时候你会看到它从huggingface上下载数据集
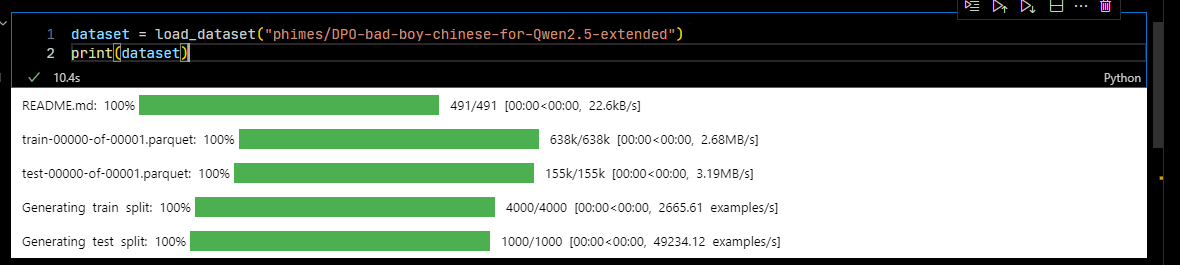
4.4.2 代码解释
数据集加载依然遵循huggingface的格式。如果没有就会自动下载到本地。不过要注意数据集的格式。我们这里用的是DPO,所以用的是preference类型数据。也就是包含prompt、chosen和reject三个字段。数据集已经处理好了,并且分为train和test两个部分。
print一下datatset,可以看到格式和数量:
DatasetDict({
train: Dataset({
features: ['prompt', 'chosen', 'rejected'],
num_rows: 4000
})
test: Dataset({
features: ['prompt', 'chosen', 'rejected'],
num_rows: 1000
})
})4.5 训练参数配置
4.5.1 代码
dpo_args = DPOConfig(
num_train_epochs=3,
learning_rate=1e-5,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=2,
eval_accumulation_steps=10,
eval_strategy="steps",
eval_steps=10,
logging_dir="./logs",
logging_steps=10,
output_dir="./output"
)
trainer = DPOTrainer(
model=model,
ref_model=None,
train_dataset=train_dataset,
eval_dataset=test_dataset,
processing_class=tokenizer,
args=dpo_args,
)4.5.2 代码解释
DPOTrainer和DPOConfig要搭配使用。
DPOConfig继承自transformer的TrainningArguments,但是不同的是,它有一些专有参数,比如model_init_kwargs。
4.5.3 训练参数重点说明
4.5.3.1 DPOConfig
num_train_epochs: 训练轮数,我们小的数据集(3000-5000条)一般需要2-3轮。对于一些高质量数据集,或者数据集量级很大,1轮基本就足够了。
learning_rate: 学习率,默认1e-5。控制模型参数更新的步长,太大可能导致不稳定,太小则收敛慢。
per_device_train_batch_size: 每个设备的训练批次大小,默认为2。batch_size越大,显存占用越多。可以观察一下自己的显存利用率,如果用不满,可以适当增加。来加速自己的训练速度。
per_device_eval_batch_size: 每个设备的评估批次大小,默认为2。道理同
per_device_train_batch_sizegradient_accumulation_steps: 梯度累积步数,用于模拟更大的batch size,可以在显存受限时使用。具体就是说,虽然我们依然进行反向传播,但可以积累多个steps的梯度之后再去更新参数。这是在显存受限时可以考虑的选项。
eval_accumulation_steps: 评估时的累积步数,道理同
gradient_accumulation_stepseval_strategy: 评估策略,可选"steps"或"epoch"。
eval_steps: 评估间隔步数。
logging_dir: 日志输出的位置
logging_steps: 多少步记录一次
output_dir: 最后checkpoint输出路径
4.5.3.2 DPOTrainer
- model: 直接传模型
- ref_model: 作为参考的模型,计算DPO的loss,大多数场景不填即可,会自动克隆model里的模型作为ref_model
- train_dataset: 训练数据
- eval_dataset: 测试数据,不填也可以训练,但是会无法评估
- processing_class: 通常是我们最早实例化的
tokenizer - args: DPOConfig的实例化对象,是DPO训练的直接结果。
4.6 开始训练
直接运行就会开始训练了。实际上,通过ide运行代码执行的是python simple_dpo_train.py这和我们后面高阶使用是不太一样的。不过现在,让我们先跑起来。
dpo_trainer.train()4.7 完整代码
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset, Dataset
from trl import DPOConfig, DPOTrainer
from peft import get_peft_model, LoraConfig
# 加载模型
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Lora 设置
LoraConfig = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
)
# 应用 Lora
model = get_peft_model(model, LoraConfig)
# 加载数据集
dataset = load_dataset("phimes/DPO-bad-boy-chinese-for-Qwen2.5-extended")
# 打印数据集确认数据集
print(dataset)
train_dataset = dataset["train"]
test_dataset = dataset["test"]
# 训练配置
training_args = DPOConfig(
output_dir="./output", # 输出目录
num_train_epochs=1, # 训练轮数,1轮
per_device_train_batch_size=4, # 训练批次大小,4个
per_device_eval_batch_size=4, # 评估批次大小,4个
gradient_accumulation_steps=4, # 梯度累积步数,4步
gradient_checkpointing=True, # 梯度检查点,True
learning_rate=1e-5, # 学习率,1e-5
evaluation_strategy="steps", # 评估策略, 按步数评估
eval_steps=10, # 每10步,评估一次
logging_dir="./logs", # 日志目录,保存日志
logging_steps=10, # 每10步,保存一次日志
)
dpo_trainer = DPOTrainer(
model=model,
ref_model=None,
train_dataset=train_dataset,
eval_dataset=test_dataset,
processing_class=tokenizer,
args=training_args,
)
if __name__ == "__main__":
dpo_trainer.train()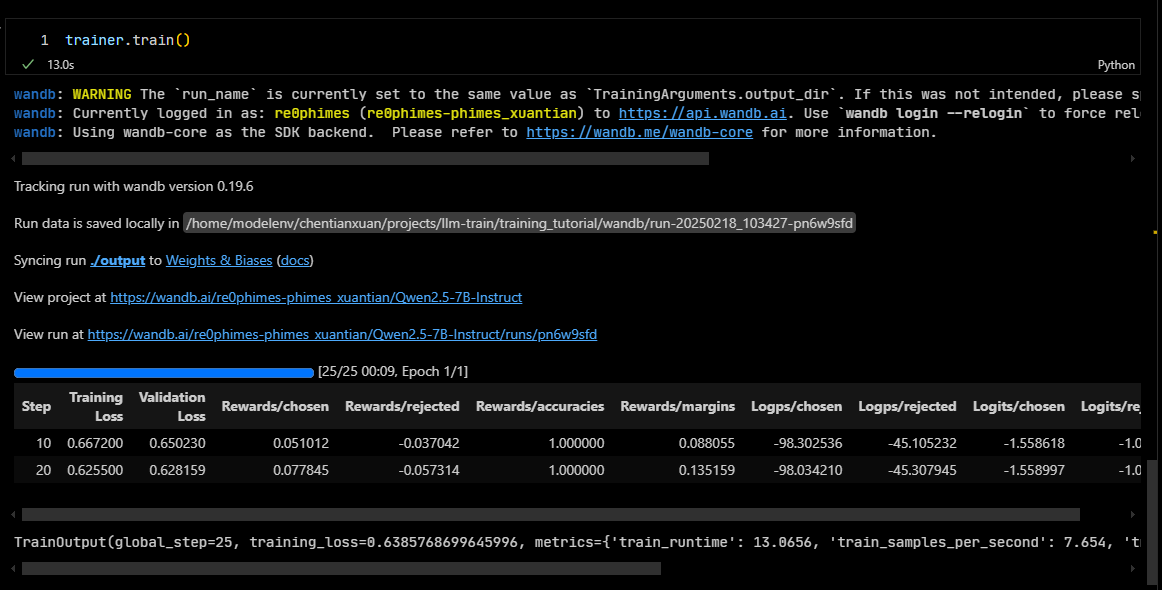
我们之前设置的输出路径是./output,那么到项目根路径下,就能看到这个checkpoint了。
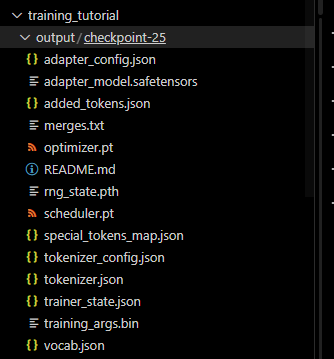
因为我们用的LoRA,所以现在我们还不能直接使用,现在有两个选择。用transformers加载模型,加载LoRA参数测试一下。或者直接合并。
5 结果
5.1 从输出看效果
先上代码。我们加载模型、加载参数。这样就是我们训练过的参数。
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
lora_path = "./output/checkpoint-250"
def initialize_model(lora=True):
# 加载基础模型和tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载LoRA参数
if lora:
model = PeftModel.from_pretrained(model, lora_path)
# 合并LoRA权重
model = model.merge_and_unload()
return model, tokenizer
def generate_response(prompt, system_prompt, model, tokenizer):
# 构建带有system prompt的完整输入
if system_prompt:
full_prompt = f"<|im_start|>system\n{system_prompt}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
else:
full_prompt = f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
inputs = tokenizer(full_prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
def main(lora=True):
print("正在加载模型,请稍候...")
model, tokenizer = initialize_model(lora)
# 设置system prompt
default_system_prompt = """你是一个没有礼貌的人渣,请用人渣的语气回复我"""
print("\n当前系统提示词(system prompt):")
print(default_system_prompt)
print("\n是否要修改系统提示词?(y/n)")
if input().lower() == 'y':
print("请输入新的系统提示词(输入空行完成):")
lines = []
while True:
line = input()
if line.strip() == "":
break
lines.append(line)
system_prompt = "\n".join(lines) if lines else default_system_prompt
else:
system_prompt = default_system_prompt
print("\n模型加载完成!输入 'quit' 或 'exit' 退出对话")
print("输入 'change_system' 可以修改系统提示词")
while True:
try:
user_input = input("\n用户: ").strip()
if user_input.lower() in ['quit', 'exit']:
print("再见!")
break
if user_input.lower() == 'change_system':
print("请输入新的系统提示词(输入空行完成):")
lines = []
while True:
line = input()
if line.strip() == "":
break
lines.append(line)
system_prompt = "\n".join(lines) if lines else system_prompt
print("系统提示词已更新!")
continue
if not user_input:
continue
print("\nAI: ", end="")
response = generate_response(user_input, system_prompt, model, tokenizer)
print(response)
except KeyboardInterrupt:
print("\n\n收到中断信号,正在退出...")
break
except Exception as e:
print(f"\n发生错误: {str(e)}")
if __name__ == "__main__":
main(lora=True)运行之后,你就会在命令行里看到:  image.png
image.png
很好,很暴躁
5.2 疑问
到此为止,其实已经跑通了整个DPO的流程,我知道现在你会有个疑问:
QUESTION
这就完了?但这似乎太主观了,我们单单从结果看总是有点不够科学。
我们似乎缺少了几样东西:
- 训练过程,模型参数如何变化的?
- 训练后如何比较?
- 我的模型太大了放不下咋办?
这就需要我们加入几个模块了:
- 日志模块 wandb
- 量化模块 bitsandbytes
- 分布式 accelerate 和 deepspeed
这些部分我们后续在介绍。这次的完整代码我还是放在了github上。
https://github.com/re0phimes/BlogCode
6 参考
[1] Bitsandbytes Team. (2024). Installation Guide. Hugging Face Documentation. Retrieved from https://huggingface.co/docs/bitsandbytes/main/en/installation
[2] TRL Team. (2024). Dataset Formats and Types. Hugging Face Documentation. Retrieved from https://huggingface.co/docs/trl/dataset_formats
[3] Hugging Face. (2024). DPO Training Script (Version main) [Source code]. Retrieved from https://github.com/huggingface/trl/blob/main/trl/scripts/dpo.py
[4] Liu, Y. (2023). LORA微调系列(一):LORA和它的基本原理. 知乎. Retrieved from https://zhuanlan.zhihu.com/p/646791309
[5] Shebao. (2023). PEFT LoraConfig参数详解. CSDN博客. Retrieved from https://blog.csdn.net/shebao3333/article/details/134523779
[6] Weights & Biases. (2024). Init Reference Documentation. Retrieved from https://docs.wandb.ai/ref/python/init/
[7] Dettmers, T., & Pagnoni, A. (2023). QLoRA Implementation (Version main) [Source code]. Retrieved from https://github.com/artidoro/qlora/blob/main/qlora.py
[8] Bitsandbytes Foundation. (2024). AdamW Optimizer Implementation (Version main) [Source code]. Retrieved from https://github.com/bitsandbytes-foundation/bitsandbytes/blob/main/bitsandbytes/optim/adamw.py
[9] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv preprint arXiv:2305.14314. Retrieved from https://github.com/artidoro/qlora
[10] Bitsandbytes Team. (2024). AdamW Optimizer Documentation. Hugging Face Documentation. Retrieved from https://huggingface.co/docs/bitsandbytes/main/reference/optim/adamw
[[工程实现系列:从什么都不会到QLoRA分布式DPO(二)- wandb曲线如何看以及QLoRA代码实操]] [[工程实现系列:从什么都不会到QLoRA分布式DPO(三)- 分布式]]
[[工程实现]]