1 写在前面
好久没更新,非常对不住打赏的佬们。本来想写一个大一点的内容,不过还是低估了内容的丰富和复杂度,一直在修修改改。先开个小坑过度一下吧。
2 TL;DL
很多人接触AI,都是直接从GPT开始的。对于一些传统的模型任务和理解不够深入,所以这次要从从最初要解决的任务出发,经过下游任务设计、预训练任务,最终落实到核心架构选择上,来完整的说明一下BERT和GPT的区别。
3 BERT和GPT的区别?
去搜索BERT和GPT的区别,一般会得到一个非常精炼的答案:
BERT是完形填空,用的是Transformer中的Encoder部分;GPT是词语接龙,用的是Decoder部分。
再丰富一点的,会说
BERT理解一个词的左右两侧内容,是双向注意力,而GPT只能看到当前词去预测下一个词,看不到后面的内容,是自回归注意力。
这肯定是对的,而且高度凝练的。所以关键的“为什么”。为什么它们会选择不同的路径?所以我认为想要了解二者的区别,应该从它设计的动机开始。而论文原文中,~~先diss了一下GPT,尽管GPT现在已经成为了主流。~~BERT在设计之出,就是一个任务驱动设计决策的成果。
We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches. The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training. For example, in OpenAI GPT, the authors use a left-to-right architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer (Vaswani et al., 2017). Such restrictions are sub-optimal for sentence-level tasks, and could be very harmful when applying finetuning based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions. (Devlin et al., 2018)
所以我们先看看BERT是为了解决哪些问题的?
4 BERT常见的下游任务
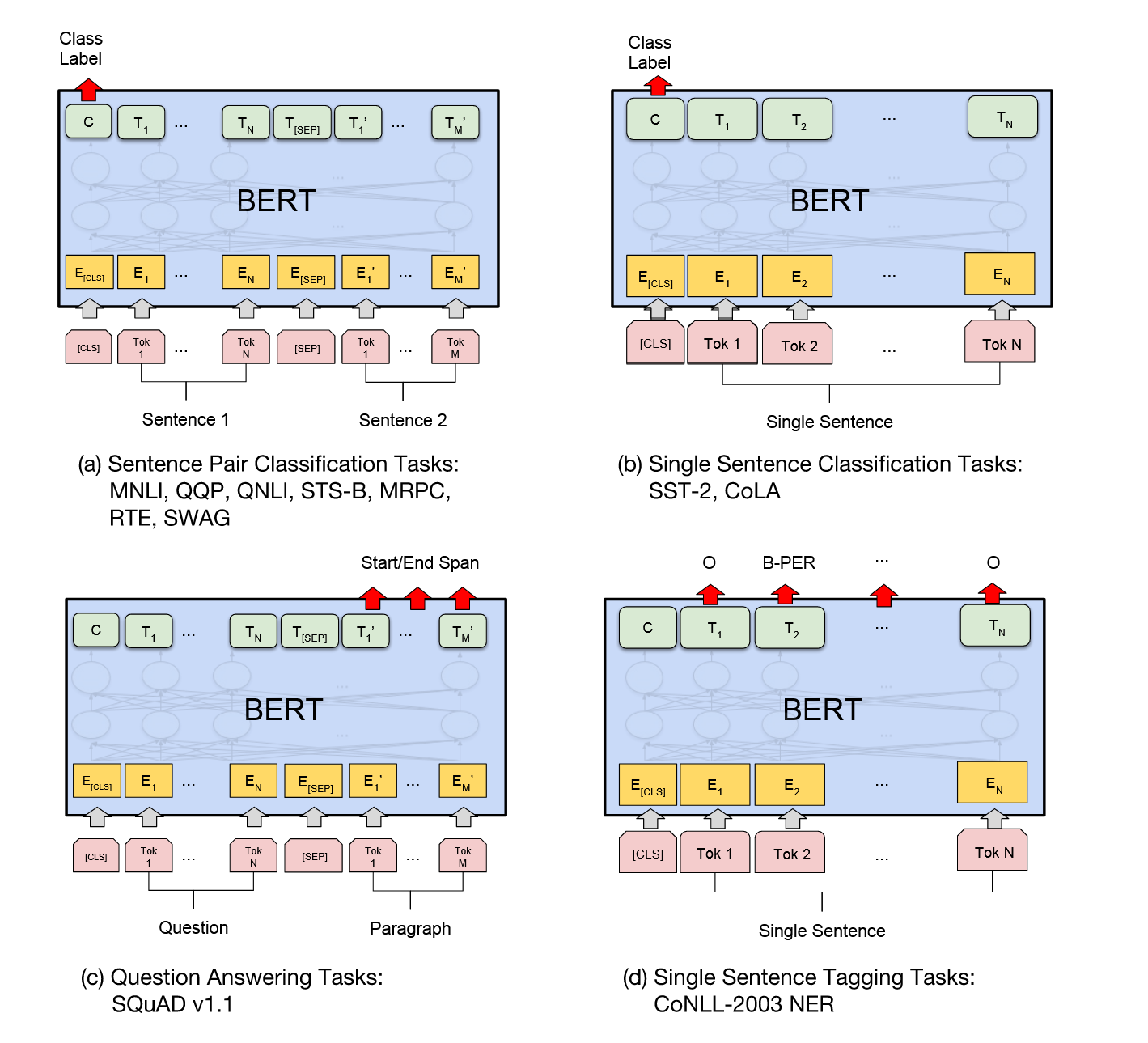
对于BERT类模型,我们可以把它的任务分为预训练任务和下游任务。在最终目的上,我们只关心他的下游任务。论文中把下游任务分为四类:
- 句子对分类 / 序列对分类 (Sequence Pair Classification)
- 单句分类 (Single Sentence Classification)
- 问答任务 (Question-Answer Tasks)
- 序列标注 (Single sentence Tagging Tasks)
4.1 序列对分类(Sequence Pair Classfication)
句子对分类,顾名思义就是输入内容是一对句子。它把两个句子(文本片段)拼接,通过[SEP]标签进行分割。其数据形态如下:
[CLS]别偷着学了行吗![SEP]能不能带带我啊?[SEP]句子对任务可以做很多,比如判断两个句子是否语义相等、矛盾或者包含。如果拿一个实际场景来看,比如github上很多issue,我们可以单纯从标题层面上去判断是不是同一个问题。
这种问题,我们有很多解法,比如文本相似度之类的。但是,我们在这里并不是这么做,在BERT中,是用[CLS] 这个special token 的最终隐藏状态。BERT的模型设计上就是人为的假设了[CLS]可以包含所有信息。(至于为什么这个设计有效,我们先按下,稍后再说)把它送入一个分类器以输出最终的判断结果。
4.2 单句分类任务 (Single Sentence Classification)
单句分类任务是对单个输入句子进行语义层面的类别判定,比如情感分析中的正面/负面分类、新闻主题分类或垃圾邮件检测。和句子对一样,输入序列由[CLS]开始,[SEP]结束,标准形态表现为
[CLS] 宝马X1是辆好车 [SEP]同样的,这个任务也是提取[CLS]的隐藏状态,然后由全连接层进行分类。如果是序列对常见的是二分类任务(语义相等或者不相等、内容矛盾或者不矛盾),那么单句分类可以根据实际情况做二分类或者多分类。比如在情感分析的任务中,我们只想要正面/负面。那我们只要将隐藏状态映射到2维度就行。但是如果我们要更详细的多分类,比如积极、愤怒、开心、沮丧等。那我们映射到对应数量维度就行。
4.3 问答任务(Question-Answer Tasks)
问答任务要求模型根据给定的问题从相关上下文段落中精确提取答案片段,典型应用包括机器阅读理解和智能客服系统。
其输入结构为:
[CLS] 问题 [SEP] 上下文 [SEP]比如:
[CLS] 光合作用的主要产物是什么? [SEP] 植物通过光合作用将二氧化碳和水转化为葡萄糖和氧气。 [SEP]。这个任务的解法和前两种不同,它不再只关心[CLS]的输出。那么,信息量从哪里来呢?BERT在这里会对上下文段落中的每一个token 的最终隐藏状态进行计算。可以粗暴的理解成,模型为上下文中的每个词都训练了两个小分类器,并打两个分数:一个是“作为答案开头”的可能性得分,另一个是“作为答案结尾”的可能性得分。模型会选择那个“开头分”和“结尾分”组合起来最高的文本片段作为答案。
回到上面的例子,模型会在“葡萄糖”这个词上得到最高的“开头分”,在“氧气”这个词上得到最高的“结尾分”,从而抽取出 “葡萄糖和氧气” 作为答案。
4.4 单句标注任务Single Sentence Tagging Tasks
序列标注任务的目标是给一句话里的每一个词都打上一个标签,比如在句子“史蒂夫·乔布斯创办了苹果公司”中,识别出“史蒂夫·乔布斯”是“人名”,“苹果公司”是“组织机构名”。它的输入形态与单句分类类似:
[CLS] 史蒂夫·乔布斯创办了苹果公司 [SEP]这个任务与问答任务有些相似,但更直接。它同样是计算输入句子中每一个token的最终隐藏状态。具体来说,BERT会把每个词元(如“史蒂”、“夫”、“乔”、“布”、“斯”)的隐藏状态向量,分别独立地送入同一个分类器中,来判断这个词元应该属于哪个标签。通常这些类型是B-PER, I-PER, O等,分别表示人名的开始、中间或非实体。
4.5 任务头
BERT的不同任务实现要搭配不同的任务头,我们直接看一下代码,大家应该都很熟悉了。
from transformers import BertSequenceClassifier, BertForTokenClassification而如果我们直接去看transformers库的实现,bert里拉倒最后,可以看到已经实现的常见任务头。有些为了预训练任务比如BertForMaskedLM,而我们之前提到的四类下游任务,常用的就是:
- BertForQuestionAnswering
- BertForSequenceClassification
- BertForTokenClassification
4.6 任务共性
回顾上述四类典型的下游任务——无论是句子分类、问答还是序列标注——我们能发现一个贯穿始终的共同点:
它们都要求模型对一段给定的、完整的文本进行深入、细致的双向理解,而非创造新内容,通过捕捉词语间复杂微妙的联系,最终给出一个分析性的结论。
5 预训练任务
既然下游任务明确了BERT必须具备深度双向理解的核心能力,那么预训练设计,就是实现这一能力的重要手段。我们首先来对比一下BERT和GPT的预训练:
5.1 BERT
BERT(我是说标准的BERT,尽管后续RoBERTa等有一些其他的思考,这就就只谈BERT)有两个预训练任务。
5.1.1 掩码语言模型(Masked Language Model)
这就是我们前面说的“完形填空”。在训练时,BERT会随机将输入句子中15%的词用一个特殊的 [MASK] 标记替换掉,然后模型的任务就是根据这个词左右的全部上下文,来预测被遮盖掉的原始词汇。
Mask的位置: 随机选择15%的词进行遮盖。这个任务强迫模型学习深度的、双向的语境依赖关系。为了猜出 [MASK] 是什么,模型必须深刻理解整个句子的结构和语义。比如
我爱[MASK]学习如果没有上下文。它可以是任何内容。可以“深度”、“机器”、“认真”,甚至“假装”。由此,模型必须学会理解左右所有token的含义,才能得出准确的结论。
5.1.2 下一句预测(Next Sentence Prediction)
模型接收两个句子A和B作为输入,然后预测句子B是否是句子A在原文中的真实下一句。这个预训练任务主要是为了让模型学习句子间的关系,比如逻辑、因果、连续性等。而这个任务的训练信号主要被 [CLS] 标记捕获。通过判断两个句子是否连贯,[CLS] 的向量表示学会了如何概括和比较两个句子的整体信息。
诶?这不是和下游任务中的判断两个句子语义是否相等非常相似么?
对!就是非常相似。不同在于目的,这里NSP的任务只做二分类,判断IsNext或者NotNext。数据集的准备也很方便。序列对分类是需要标注的,而这里是自监督的。我只要把小说里的两句话直接拿出来,程序上给他组合后就可以作为IsNext的数据,而随机抽取两句再拼接就是NotNext。
5.2 GPT
与BERT为“理解”而生的双向策略不同,GPT系列模型从一开始就做了一种选择。其核心预训练任务只有一个,自回归语言模型。
5.2.1 自回归语言模型(Autoregressive Language Model)
这个任务的目标极其纯粹:根据一个词之前的所有上下文,来预测这个词本身。它严格地按照文本从左到右的自然顺序,逐词学习语言的流向。例如,对于句子 我喜欢飞机,GPT在训练时会执行以下一系列预测:
- 当看到
我时,模型必须学会预测下一个词是喜欢的概率最高。 - 当看到
我 喜欢时,模型需要预测出飞机。 - 当看到
我 喜欢 飞机时,模型需要考虑后面是“模型”还是“杯”
这种训练方式的本质是强迫模型学习一个条件概率分布,即在给定前面所有词的条件下,下一个词应该是什么。为了能准确地“接龙”,模型必须在其内部表示中,悄无声息地学会语法规则、事实知识、上下文逻辑,甚至是某种写作风格。
5.3 注意力形态的不同
所以我们综合来看,BERT和GPT的想要解决的问题不同,所以选择了不同的注意力形态。前者可以关注所有的内容,后者则只能看到当前词之前的内容。
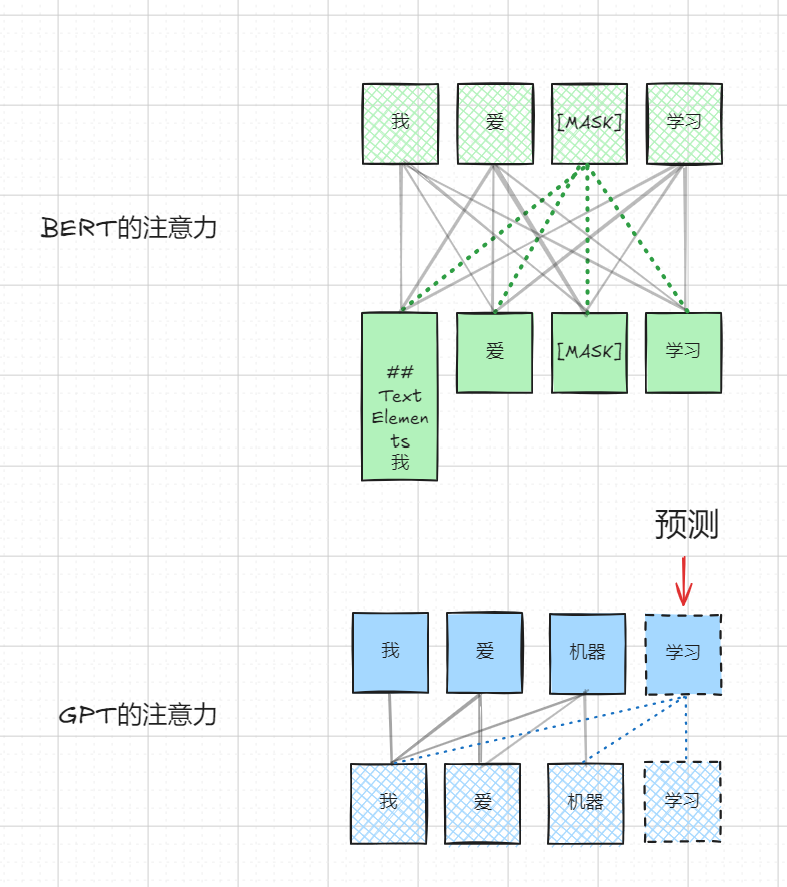
于是现在,我们终于可以回过头来看一下最初说的“BERT用的Encoder,GPT用的Decoder”。看看架构上的区别。
6 架构区别
不论是GPT还是BERT,对原始方案都是有一点点改动的。先说GPT
6.1 GPT
6.1.1 原始Transformer Decoder:
在原始的transformer中,decoder模块设计用于序列到序列任务,包含三个部分:
- 掩码多头自注意力(Masked Multi-Head Self-Attention): 使用前瞻掩码(causal mask),确保每个位置只能关注之前的位置(包括自身),防止信息泄露。这是实现自回归生成的关键。
- 编码器-解码器注意力(Encoder-Decoder Attention): 这是Decoder独有的子层。它以Decoder掩码自注意力的输出作为查询(Query),以Encoder栈的最终输出作为键(Key)和值(Value)。这允许Decoder在生成每个目标词元时“关注”输入序列的编码表示。
- 全连接前馈网络(Position-wise Feed-Forward Network): 与Encoder类似。
6.1.2 GPT的变体:
GPT的最主要修改是移除了编码器解码器注意力部分。因为GPT是一个纯粹的生成模型,它只需要根据前文预测下一个词,所有的注意力都会经过多次的堆叠,在当前最后一个token下。所以,它不需要编码器-解码器部分的双向注意力了。
所以GPT的架构中transformer blocks只有两个部分:
- 前瞻掩码自注意力机制
- 全链接前馈神经网络
当然这里GPT对decoder部分的改造并不是本次的重点。
6.2 BERT
BERT其实是直接直接使用encoder部分,在这个部分,和图里的是一致,包含两个部分:
- 多头自注意力机制: 无掩码,允许每个位置关注序列中的所有其他位置(包括自身),实现双向上下文编码。
- 全连接前馈网络(Position-wise Feed-Forward Network): 对每个位置独立应用全连接层进行非线性变换。
但是BERT在这个基础上做了一些别的修改:
第一个是输入表示进行扩展:它引入了两个的special token:[CLS]和[SEP]。(其他三个PAD、MASK、UNK本来就有)。
[CLS]:Classification的缩写,放在每个输入序列的开头。它的最终隐藏状态(hidden state)通常被用作整个序列的聚合表示,用于分类任务。[SEP]:Separator的缩写,用于分隔句子。- 如果我们只有一个句子(单句任务),我们就放在句末。比如
[CLS]宝马X1是一辆好车[SEP] - 如果我们是句子对的任务 (NLI和QA任务) ,它放在第一个句末和第二个句末。比如:
[CLS]宝马X1是一辆好车[SEP]它是身份的象征[SEP]
- 如果我们只有一个句子(单句任务),我们就放在句末。比如
[MASK]: 这是 BERT 预训练任务(Masked Language Model, MLM)的核心。在训练时,一些 token 会被随机替换为[MASK],模型需要预测这些被遮盖的原始 token。从而形成我们的"完形填空"。一个句子因为是随机选择位置,可以有多个不同的
[MASK],可以从一个句子里得到多个训练的数据。比如,原始的句子是宝马X1是一辆好车,那么句子A可以是[CLS]宝马[MASK]是一辆好车[SEP],句子B可以是 `[CLS]宝马X1是一辆[MASK]车[SEP]
第二个是段落嵌入(Segment Embeddings) 的表示:之前的文章在介绍GPT的时候,我们在输入部分的模块是词嵌入+位置编码。但是在BERT这里,我们多了一个段落嵌入。在句子对例子中位置嵌入是用来表示不同句子。
所以在BERT中,数据在没有添加MASK以前,是下面这样一个流程。
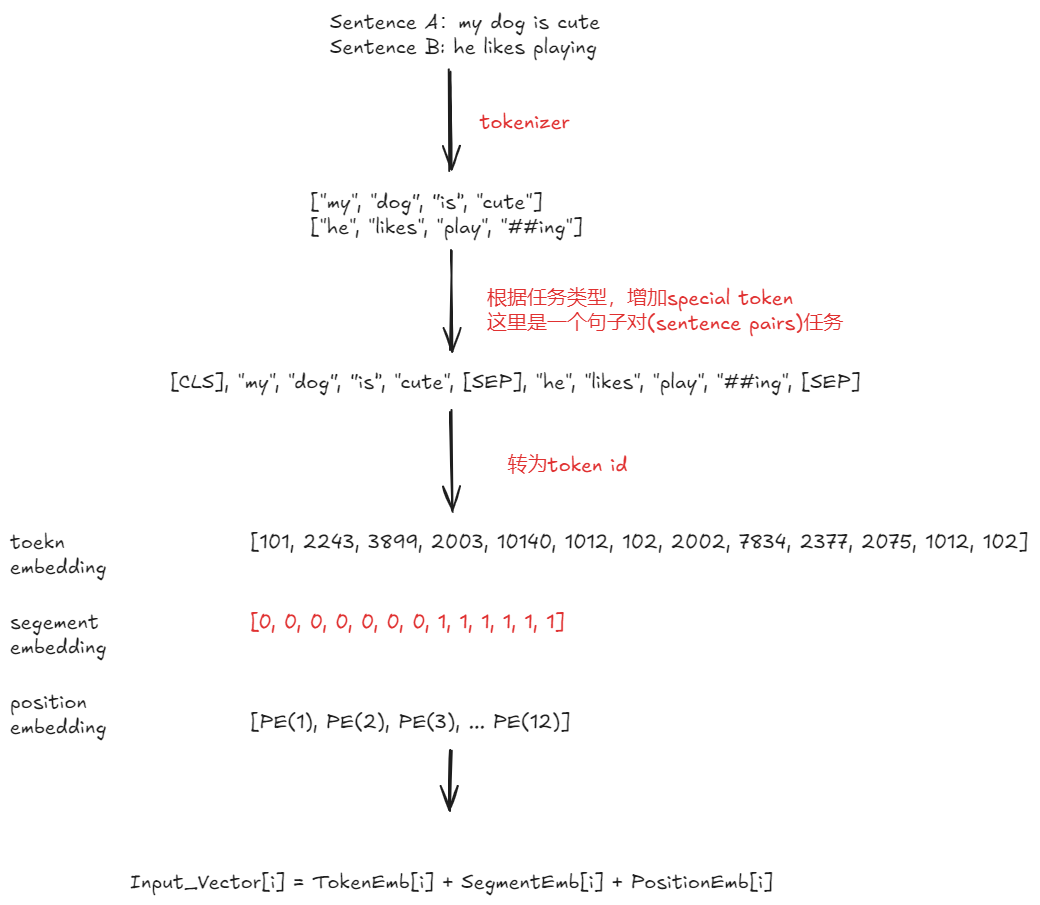
其实还有一些别的改动,比如位置编码的变化,分词方式等。但是GPT也有这样的改动。所以我认为最主要的区别还是[CLS]、[SEP]以及段落嵌入。
7 深入思考
说到现在,我们似乎已经搞清楚BERT和GPT的区别了。从下游任务出发,任务目标引导了这个架构的选择和模型的设计。但是这里有些东西还是有点不够清晰。我们稍微多想一点点,来进一步深化理解。
7.1 问题1:
从直觉上来看,BERT的双向理解似乎比GPT的单向更为有效?为什么现在GPT反而成为了一种主流?而且效果还很好。
还是从任务出发,我们已经知道BERT是怎么去做的。如果我们想知道“中国的首都是哪”。对于BERT,它需要你给定一个段落,并且确定答案在这里面。比如:
[CLS] 中国的首都是哪? [SEP] 中国,全称中华人民共和国,首都位于北京... [SEP]但是一些实际的任务是,我不知道在哪,我也没有答案。所以我需要问:
User: 中国的首都是哪?
Model:北京所以本质上,他们还是两种场景。BERT和GPT在对应任务上各有优势。而且GPT可以通过prompt把任务转化。比如分类任务,BERT可以给出积极、消极等区分。
[CLS]我喜欢北京[SEP]对于GPT,也可以通过提示词把续写变成分类或者其他任务:
User:判断‘我喜欢北京’的情感:积极/消极。答案是:
Model:积极所以,BERT的双向理解,是在给定边界内进行深度分析的最高效方式。它是一个需要“喂数据”的分析引擎,在信息抽取、语义匹配等需要精准理解的场景下依然是顶尖选择。 GPT的单向生成,通过海量预训练将知识内化于模型本身,并通过“生成下一个词”这一简单而统一的任务,实现了通过提示词来无限泛化其能力。
7.2 问题2:
既然GPT已经可以解决我们问答的需求了,为什么还需要BERT?
现实世界不是只看任务是否解决。还得看“有没有用更少的资源解决”或者“做的快不快”等。实际上,在工业界,BERT依然是一个非常高效的方案。
首先,从任务特化和计算效率上看,BERT这类模型是“专家”。对于信息抽取、情感分析、文本分类等纯粹的“理解”任务,BERT的编码器架构可以并行处理整个文本,瞬间完成分析,其速度和计算资源消耗远低于需要逐词生成的自回归类。我们可以微调多个专精的BERT,在不同的地方用或者和大模型结合。
比如我常用的一个方案就是微调BERT做垂类领域的初步分类筛选。同时可以把logits取出来,取置信度,只有一定置信度以上的保留(这里简化的说,实际可以做的更复杂一些),不合适的就丢给大模型就好了。是一种面对“既要又要”需求的很方便的方案。
7.3 问题3:
那BERT为什么不能跟GPT一样做生成任务?
从架构角度来说,BERT在预训练时,接触到的[MASK]标记有大约80%的概率是随机出现在句子中间的。之前说过,BERT是在拥有充分的、双向的上下文(左边和右边都有词)的情况下,去推断一个被遮盖的词。 它的整个“世界观”都是建立在“信息完整的前提上。
如果我们不管它的这个前置的预训练流程,直接让它做生成任务。用一个直观的比喻就是:老师一直教的加法,比如100+23,然后突然,考试考你200 * 66。
就算我们抛开这个矛盾。我就是MASK最后一个词去做行不行?
行,肯定行,但是会有几个问题。
7.3.1 一次性生成的方案
输入: [CLS] 我喜欢飞机 [MASK] [MASK] [MASK]. [SEP]
这里的问题是:无法确定生成长度:我们应该在后面加多少个 [MASK]?3个?5个?10个?我们事先无法知道续写的内容有多长。
另一个问题是:BERT在一次前向传播中,会同时、独立地预测所有 [MASK] 的内容。它在预测第一个 [MASK] 时,并不知道第二个 [MASK] 会是什么。这会导致生成的内容毫无逻辑,甚至可能是乱码。那么这种输入下,假设我们就认为是3个MASK,会变成同时预测3个的MASK。那就可能预测出:
我喜欢飞机坦克another热气球
7.3.2 那我就跟GPT一样一次次生成
第一步:
`[CLS] 我喜欢飞机 [MASK]. [SEP]`
第二步:
`[CLS] 我喜欢飞机坦克 [MASK]. [SEP]`
第三步:
`[CLS] 我喜欢飞机坦克和 [MASK]. [SEP]`看着似乎没有什么问题,这不就是GPT的生成方式么。问题就在于BERT的双向注意力。BERT的每一层网络都会让序列中的所有词相互进行注意力计算。这是一个完整的、涉及整个序列长度的复杂计算过程。
第一次, 我们的双向注意力会计算序列一:
[CLS] 我喜欢飞机 [MASK]. [SEP]
计算之后, 我们得到了“坦克”这个新词。然后生成了一个新的序列,我们称为序列二:
[CLS] 我喜欢飞机坦克 [MASK]. [SEP]
从BERT的角度看,这是一个全新的、与上一步毫无关联的输入序列。为了预测新的 [MASK],模型必须从零开始,再次对这个更长的序列进行完整的双向注意力计算。
BERT的编码器架构没有任何机制来“记忆”或“复用”上一步的计算结果。每增加一个词,都相当于要求你为了写下一个词的摘要,而把整本书从第一页重新读一遍。关键你(BERT)确实就是,读完了就忘了。
GPT不同,就算你没有深入了解过,你也肯定也听过KV cache这个词。这为GPT提供了一个地方缓存之前输入的K向量和V向量,相当于我们不用重新计算整个输入序列。
7.4 问题4:
为什么CLS可以表示整个序列的信息?
先说说其他token,如果我们直接随便选一个token,那么问题就出现了,每个token都是有自己含义的,所以或多或少会有不同的侧重。所以随机选一个可能会导致语义的偏差。那我们就需要一个空白的token来对全局进行表示。这就是有了CLS。
所以叫它什么都行,总而言之,这个token原本是空白的。所以在预训练和下游任务(比如单句分类,因为单句分类我们拿得CLS的hidden state)的时候,可以被反向传播的计算梯度损失来迫使模型的参数优化,让CLS必须有足够丰富的全局语义信息来完成分类。
问题5:
那必须要用`[CLS]`吗?
这还真不是,[CLS]虽然是被当做一种标准做法,但是一些场景下我们可以有一些别的选择。
在BERT出现之前,处理句子级别的任务(如情感分类、句子对相似度判断)通常有两种主流方法,RNN/LSTM或者CNN/Polling。
本质上两套假设
RNN/LSTM的逻辑是:模型顺序读取整个句子,并将最后一个时间步的隐藏状态(hidden state)作为整个句子的表示。这种方法的逻辑是:最后一个状态“看”过了所有前面的词,理应包含了全句信息。但它有长距离依赖问题,句子末尾的词权重可能过高。
看上去[CLS]在句子开头,似乎也有问题,但Transformer的自注意力机制是双向和全局的,在BERT中,我们允许[CLS] token在计算其表示时直接关注序列中的所有token(无论位置远近),因此[CLS]不会面临类似RNN的长程依赖问题。其有效性源于这种全局注意力而非位置。
顺带一提 LSTM/RNN这种最后一个词的权重看上去很像GPT,但是LSTM/RNN序列开头的信息需要经过每一个中间时间步的迭代计算,才能传递到末尾。这是一个漫长且有损的“接力”过程,极易导致长距离依赖问题(信息遗忘)。GPT和之前说的一样,尽管我们也有上下文的问题,但是单次输入的时候,头尾token以及中间的token是会一起计算注意力,这是一个并行的过程,不是“接力”。
那我们能不能像CNN那样采用池化?CNN/Pooling使用卷积神经网络在句子上提取局部特征,然后通过池化(比如最大池化或者平均池化)操作将所有词的表示聚合成一个定长的句子向量。这种方法的逻辑是:平均所有词的贡献或抓住最关键的词的贡献。
先前已经说过了随机选一个不行。那我采用池化的方式不就行了?还真说对了,池化确实是一个思路,尽管池化有池化的局限性,但是某些任务上来说的[CLS]未必就比池化好,尤其是对于语义相似度匹配等任务,像Sentence-BERT这样的模型就证明了,在特定微调框架下,平均池化策略的效果显著优于直接使用未经优化的[CLS]向量。(具体就不展开说sentence-BERT了,有兴趣的大家自己看论文吧)
8 写在最后
还有很多坑比如ROPE,MOE等没填,后续会加紧填坑的。其实BERT还是有很多可以说的,这次就做一个引子,简单介绍一下。
9 参考
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. OpenAI. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding (Version 2). [Preprint]. arXiv. https://doi.org/10.48550/arXiv.1810.04805
- Sharkey, E., & Treleaven, P. (2024). BERT vs GPT for financial engineering. [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2405.12990
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. [Preprint]. arXiv. https://doi.org/10.48550/arXiv.1907.11692
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence embeddings using siamese BERT-networks. [Preprint]. arXiv. https://doi.org/10.48550/arXiv.1908.10084