1 TL;DR
本文的目标在于理清楚一个核心问题:为什么主流大模型纷纷从传统的多头注意力转向了MQA、GQA、MLA等变体? 关键在于解码阶段的 KV Cache 及其引发的 “内存墙” 问题。内容如下:
- Prefill 与 Decoding 两阶段的本质区别。
- KV Cache 如何以空间换时间,解决重复计算。
- KV Cache 如何从“救星”变为“瓶颈”,导致严重的显存带宽压力。
- MHA → MQA/GQA/MLA 的演进逻辑:通过减少需要缓存的键值头(
num_key_value_heads)数量,直接“瘦身”KV Cache,是突破内存墙最直接的架构优化手段。
这个系列的共计三篇。作为第一篇,算个引子,本篇主要还是先串一串逻辑,把叙事部分讲好。
另外,我知道光看文字和公式,[b, h, L, d] 这些维度的变化在脑子里还是容易打结。为了让你更直观地看到数据在显存里到底是怎么流转的,我特意让AI 手搓了一个可视化页面,建议配合本文食用:
我把这个维度变换的流程,放在了MHA推理流程。(更建议自己手动推一遍)
2 优化的目标:从Attention的选择困难开始
对于现代大模型架构,各个transformer的组件已经逐渐被更新的模块替换。以attention为例,可以看到千奇百怪的attention,有从硬件和框架上优化的,也有结构上优化的。不同模型选择各不相同,比如Llama、Qwen3-Next都采用了GQA,Deepseek的MLA。抛开oLMO 2 这种研究性质模型,minimax的M2这样的商业落地的模型,反而采用了MHA这样的传统的结构。
也就是说研究者对不同的模块选择依然有各自的见解和选择。这里先按下对不同Attention直接介绍,我们先放出一个问题:我们对Attention的优化,到底在优化什么?
要理解这个问题,我们先从推理的两个阶段开始。
3 推理的两个阶段
在大模型的推理阶段,分为两个步骤:
Prefill 阶段:当模型接收到用户的初始提示(Prompt)时,它处于预填充(Prefill)阶段。此刻,模型拥有完整的输入序列,其任务是并行计算所有输入词元的中间表示,并生成第一个输出词元。
这一过程为矩阵与矩阵的乘法(GEMM),计算高度密集,充分利用GPU的并行计算单元,属于典型的计算受限 场景。
然而,从生成第二个词元开始,模型便进入了解码(Decoding)阶段。
Decoding 阶段:每生成一个新词元,模型在注意力计算中都需要让当前词元的
如果不做任何优化,那么每一步都需要为所有历史词元重新计算其键(Key)和值(Value)向量。问题在于,历史词元的
有点理解不来是吧,我们手推一下。
4 MHA的计算流程
4.1 MHA的prefill
整个MHA的prefill阶段可以凝练成下面这些内容:
模型接收到完整的输入序列,其完整的序列可以写作。
通过线性层 [b, h, L, d_h] 以支持多头并行计算,随后通过 [b, h, L, L] 的完整注意力分数方阵,用于计算序列内所有 Token 之间的相互关注程度。
经过掩码处理与 [b, L, d],并依次通过Add&Norm及 FFN等 模块。
虽然模型在各层并行计算了全量序列的表征,但为了生成第一个预测词,模型最终仅提取输出矩阵最后一行的 [b, 1, d] 向量,同时将此阶段产生的全量 K 和 V 存入 KV Cache,作为后续增量计算的基础。
用一个简化的例子来推一下,如果我的输入是“别偷着学了带带我啊”,可以表示为[“别”, “偷着”, “学了”,“带带”,“我”,“啊”]。我们简化维度,设为6。也就是一个token会被表示成一个[1, 6]的向量,合起来就是一个[6, 6]的矩阵。在一个多头注意力下,我们的head为2,则会得到如下过程:
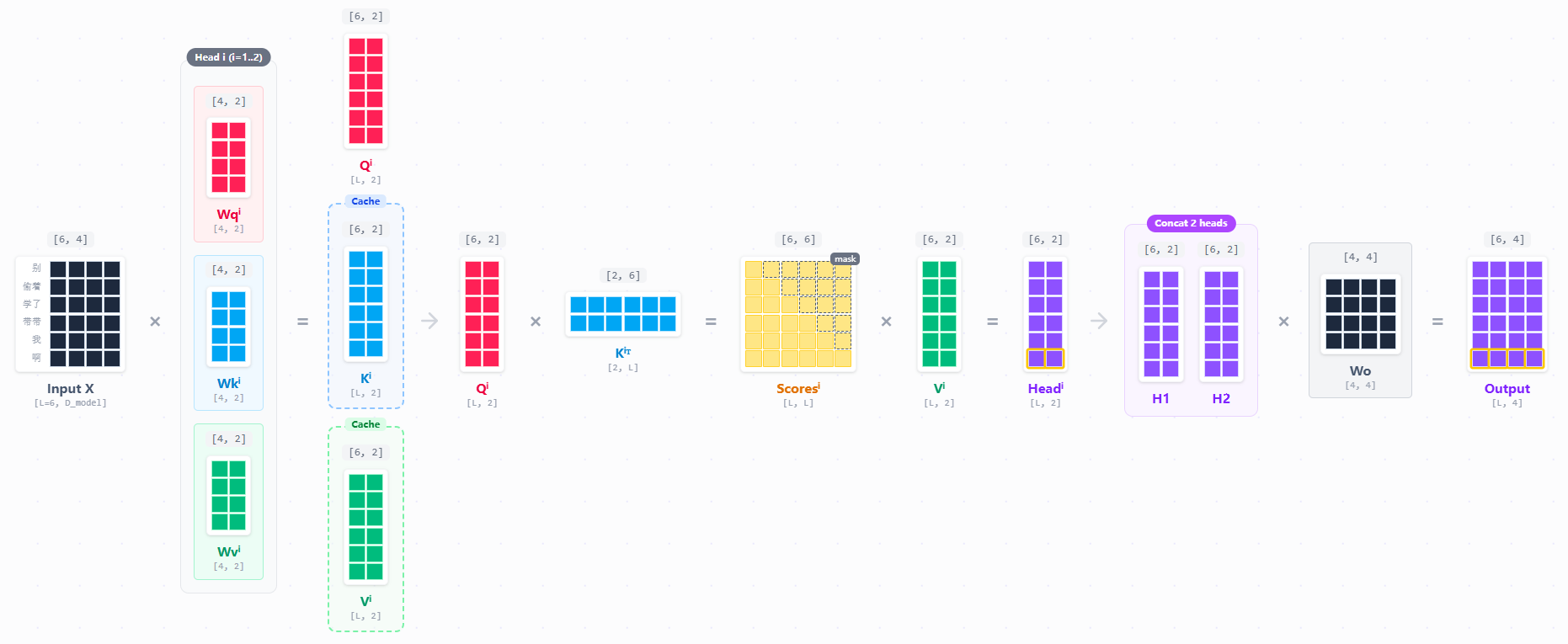
我们每个head,都要执行一次attention的score计算:
在 Transformer 结构中,每一层的输出向量(Hidden State)中,只有最后一行(即最新 Token 的向量)会被传递到最终的LM Head或下一层对应的位置 ,用于生成下一个预测结果。
Prefill阶段,因为所有的输入我们都没见过,需要并行的计算整个Attention矩阵,然后取最后一行进入LM Head进行下一个token预测。但是问题在于当我们第一个token出来之后 (进入decoding阶段),我们需要计算下一个token。自回归的特性让我们生成第
4.2 MHA的decoding
4.2.1 如果没有kv cache
如果没有kv cache,我们完整的迭代计算prefill之后的每一个next token,其过程都是要完整的计算一遍所有内容,和prefill阶段没有任何区别。
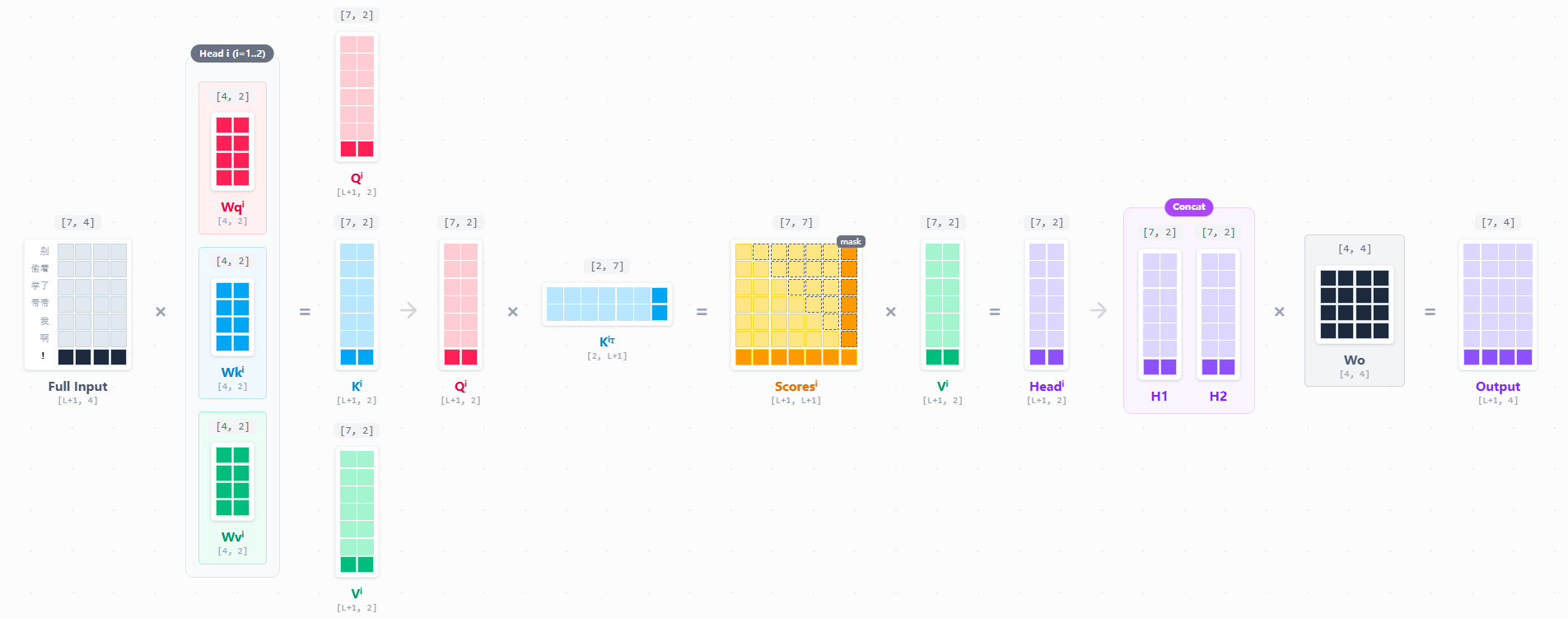
但是仔细观察一下就能发现,QKV以及我们的attention score,浅色的部分都是计算过的。在上面的流程中,其实我们是重新计算了一遍。这种做法使得生成
随着 Context Length 的增加,计算资源被大量浪费在“重复造轮子”上。
- 当
时,我们重新计算了前 99 个 token 的 K 和 V。 - 当
时,为了这 1 个新 token,我们重新计算了前 4095 个 token 的 K 和 V。
很明显,这是非常不合理的。
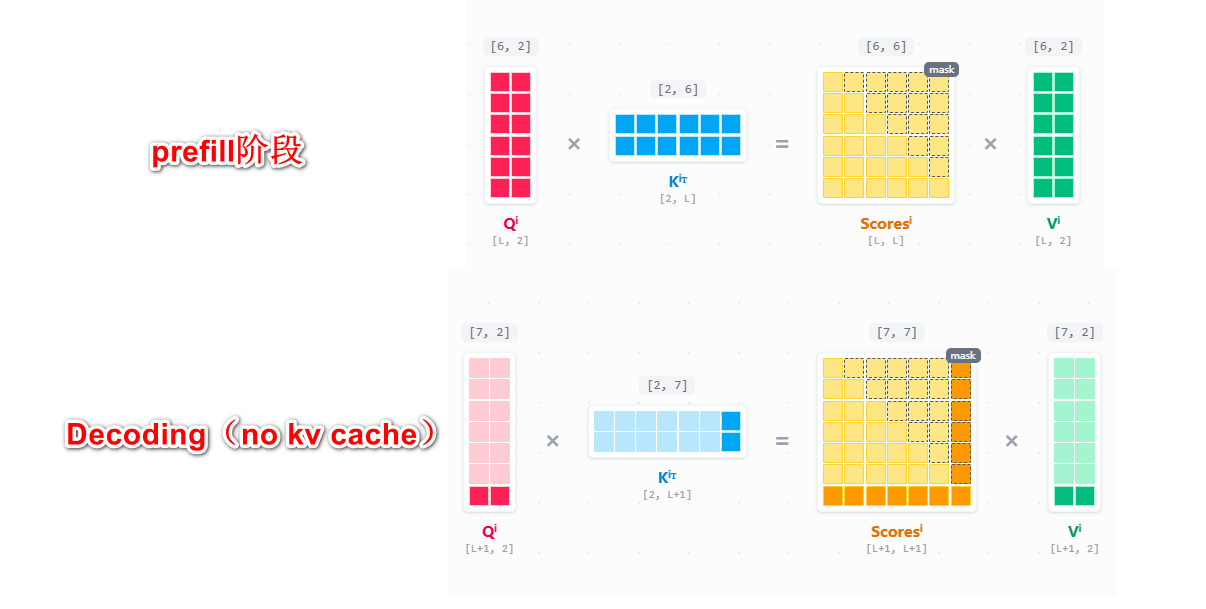
既然 $x_1$ 到 $x_{t-1}$ 的 K 和 V 矩阵在之前的步骤中是固定的,为什么不把它们存下来?
4.2.2 有kv cache
对的,既然我们已经计算过了K和V了,我们只要把内容存下来,等下一次decoding的时候,再拿出来就好了。
于是真正的计算流程就变成了这样,对于K和V,我们只要把新计算的K和V提出来,和新计算的
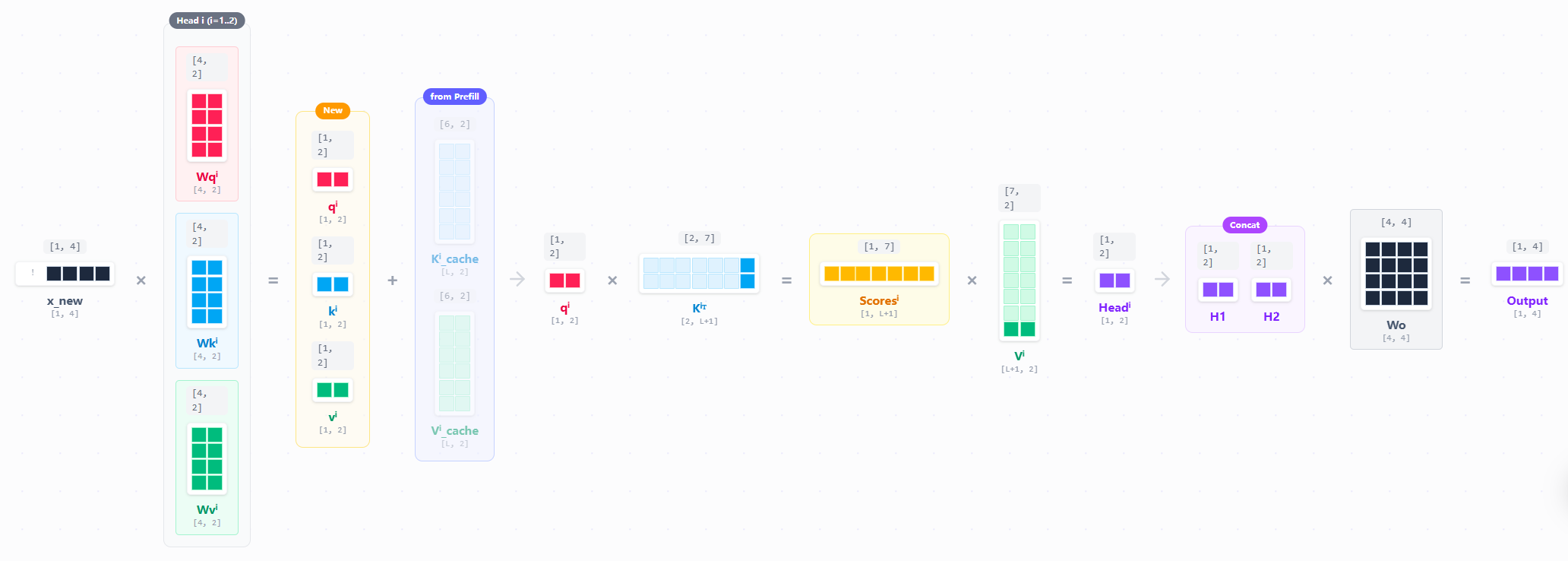
现在,生成第
其中,
接着用权重矩阵
此时生成的
当前的查询向量
很明显,由于
将最新的
这就是KV cache。 我们再对比一下区别:
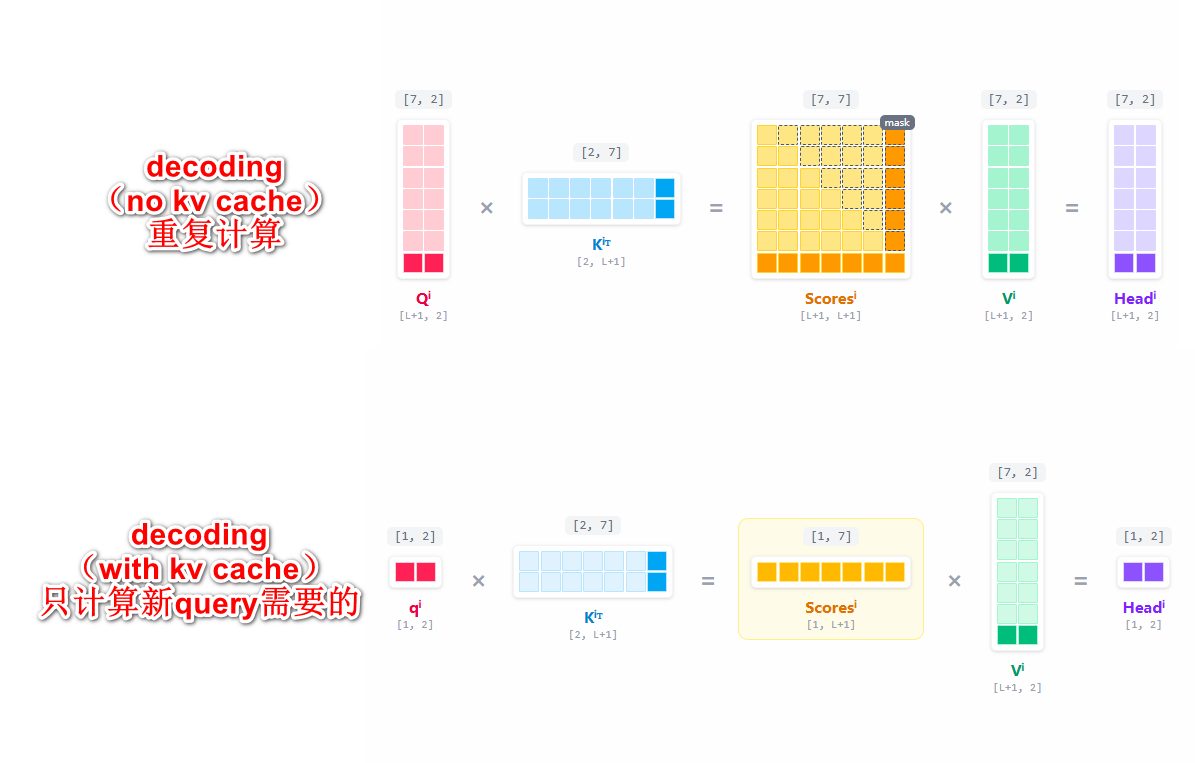
题外话,这也正好回答了知乎上一个问题 ”为什么没有Q cache",因为很多人没有实际理解模型输出的数据变化,推理阶段的decoding的输入输出,以及中间数据变化只要了解了,就很直观。
对于decoding,我们拿t-1个token的embedding去计算。这是一个向量,其操作是GEMV,出来的也是一个向量
5 KV Cache 带来的问题
KV Cache 的本质是 空间换时间。KV Cache 节省了计算量,但需要占用显存。
5.1 KV Cache的显存占用
每个 token 需要存储的显存量为:
其中:
2:代表 K 和 V 两个矩阵。n_layers:模型层数。n_heads x d_head:其实就是(模型的维度)。 P_precision:精度(FP16 为 2 bytes)。
拿经典的MHA结构大模型算一下,这里用Llama-2-7B(新模型都大多已经换了GQA或者MLA了)为例,其config.json如下:
{
"architectures": [
"LlamaForCausalLM"
],
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_position_embeddings": 4096,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32,
"pad_token_id": 0,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.30.2",
"use_cache": true,
"vocab_size": 32000
}这是一个标准MHA。
n_layers: 32d_model: 4096 (即 n_head × d_head)P_precision: FP32 (4 bytes)
这看起来不多?让我们把context length加长,如果Context = 4096,那就要占用
2G看着也还行,那如果并发上来呢。比如batch size是32呢。
也就是说,如果投入到商用,只要用户量稍微上来,一张 80GB 的 A100 甚至塞不下 Batch 64 的 KV Cache。
5.2 显存带宽
除了显存问题(不是主要问题),更麻烦的其实是显存带宽。GPU中有两个部分,一个是HBM(显存,有时候我们它是VRAM)另一个是SRAM(计算单元)。我们的attention计算是在计算单元中的,但是缓存的KV是在HBM里的。
既然之前我们已经缓存过K和V,但是
这时候KV cahce用空间换来的时间又迎来问题了。因为搬运也是要成本的。而决定是搬运效率的就是显存带宽。
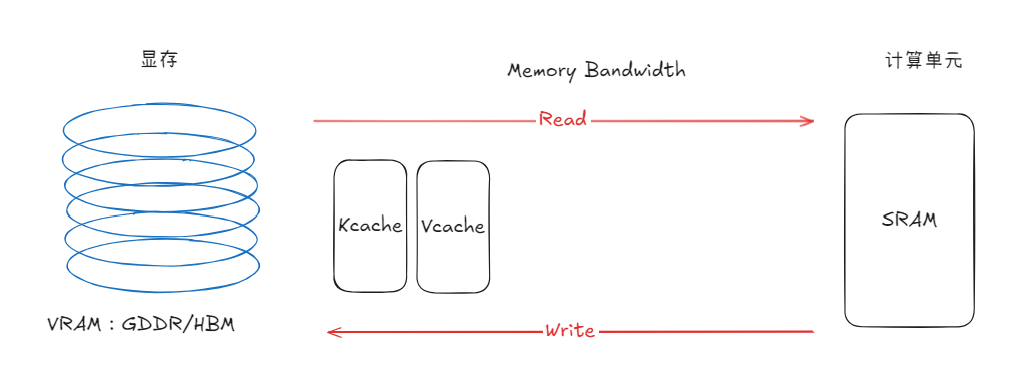
显存带宽有大有小,这里是大概的一个范围。具体可以参考:nvidia-ada-gpu-architecture.pdf 或者其他Nvidia架构的官网资料。
| 架构 | 显卡 | 显存带宽 | FP16/BF16 算力 | 显存类型 |
|---|---|---|---|---|
| Volta | Tesla V100 | 900 GB/s | ~125 TFLOPS | HBM2 |
| Turing | Titan RTX | 672 GB/s | ~130 TFLOPS | GDDR6 |
| Ampere (计算卡) | A100 | 2039 GB/s | 312 TFLOPS | HBM2e |
| Ampere (游戏卡) | RTX 3090 Ti | 1008 GB/s | ~160 TFLOPS | GDDR6X |
| Hopper | H100 (SXM) | 3352 GB/s | 989 TFLOPS | HBM3 |
| Ada Lovelace | RTX 4090 | 1008 GB/s | ~330 TFLOPS | GDDR6X |
看着不直观没法理解对吧?老规矩,算一遍。
还是以LLaMA-7B为例,假设我们现在用FP16,也就是2Byte,那么权重约为 14GB。假设 KV Cache 此时积累了 1GB。需要搬运的总数据量 15GB。
一张 A100 的显存带宽约为
生成 1 个 Token 所需的时间:
- 搬运数据时间:
。 - 计算时间:7B 模型大约对应 14G FLOPS。A100 算力 312 TFLOPS。计算时间
。
对比一下搬运时间/计算时间:
7.5/0.04=187.5

好好好,187.5倍,也就是说。搬运的时候,计算单元大部分时间是闲着的。这就真不能忍了,我摸鱼也就算了,显卡也摸鱼?而且这只是1G的KV Cache,如果你的KV Cache积累到10G、20G或者更多呢?
这种现象称为内存墙(Memory Wall)。可以通过下列公式计算:
架构的问题,我能咋办?
要么加带宽(买更贵的 HBM),要么减少需要搬运的数据量(尤其是 KV Cache)。
我们再来审视一下KV Cache的公式:
让我们用排除法一个个看:
- 2:这是 Attention 机制定义的基石。只要是自注意力,就需要 K 和 V 两个矩阵来计算相关性,这是物理底层,动不得。
- n_layers(层数):这是模型“深”度的体现,直接决定了模型的推理能力和抽象层次。动了可能会降智,要谨慎考虑。
- d_head(头维度):通常是 128,这决定了每个头能容纳多少特征信息,砍了也会严重影响智力,不好动。
- P_precision(精度):从 FP16 (2字节) 降到 INT8 (1字节) 甚至 INT4 (0.5字节),这确实是个思路,但那是另一个优化方向(可以叠加使用),这里先按下不表。
现在比较好动的目光,锁定在了
终于,我们回到了最初的问题。
我们对Attention的优化,我们到底在优化什么?
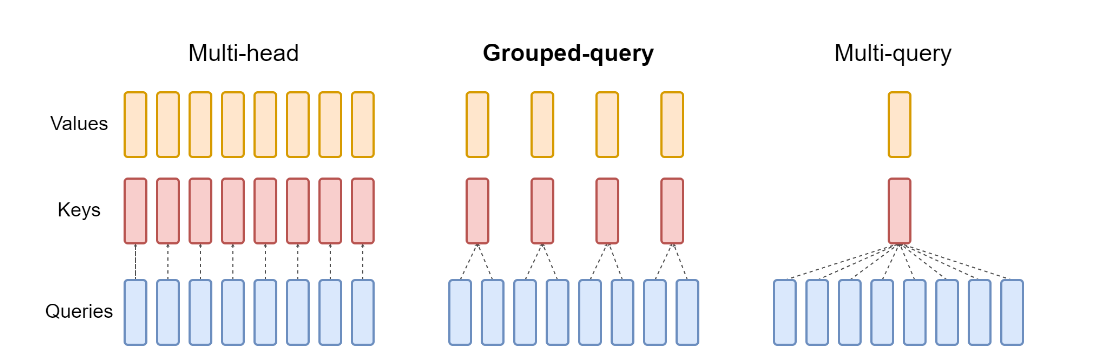
6 MQA 与 GQA
MQA(Multi-Query Attention) 和GQA(Grouped-Query Attention)的核心机制是通过减少键值头的数量( num_key_value_heads),来降低Decoding阶段需要缓存和从显存中读取的KV Cache大小,从而缓解“内存墙”带来的带宽瓶颈,提升生成速度。
MQA 通过让所有查询头共享单一组键值头来达成极致的缓存压缩,但这通常会导致模型输出质量的可感知下降;
GQA 则通过将查询头分组并让每组共享一组键值头,提供了一个可灵活配置的权衡点,允许模型开发者在推理速度和模型质量之间进行更精细的平衡。
6.1 MQA
让所有的 Query Head 共享同一组 Key Head 和 Value Head。其直接结果就是
head的数量少了32倍,对比MHA的版本,KV Cache 大小直接少了32倍。
6.2 GQA
这里的 Group 数就是最终 KV Head 的数量,即
每个 KV Head 负责服务的 Query Head 数量为:
我们算一下如果 Llama-2-7B 换成 8 组(Group=8) 的 GQA 是多少:
Head 的数量从 32 变成了 8(每 4 个 Query 共享 1 个 KV),对比 MHA 的版本,KV Cache 大小少了 4 倍。
6.3 MLA
MLA(Multi-head Latent Attention) 代表了另一种优化思路。与MQA、GQA直接减少KV头的“物理”数量不同,MLA的核心在于改变Attention的计算结构。
MLA同样能有效缓解KV Cache的内存压力,但其实现路径并非直接调整 num_kv_heads,而是在计算图层面进行了重构,以达到类似的优化目的。
下一篇中也会同步进行说明。
7 写在最后
到这里,一个Attention优化的逻辑算是串差不多了。下一篇展开MQA、GQA和MLA的具体优缺点、难点等。
8 参考
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebrón, F., & Sanghai, S. (2023). GQA: Training generalized multi-query transformer models from multi-head checkpoints. arXiv. https://arxiv.org/abs/2305.13245
Hugging Face. (n.d.). Optimizing inference. Transformers Documentation. https://huggingface.co/docs/transformers/llm_optims
Jin, S., Liu, X., Zhang, Q., & Mao, Z. M. (2024). Compute or load KV cache? Why not both? arXiv. https://arxiv.org/abs/2410.03065
NVIDIA. (n.d.). Ada Lovelace architecture. https://www.nvidia.com/en-us/technologies/ada-architecture/
NVIDIA. (n.d.). NVIDIA Ada Lovelace architecture white paper [White paper]. https://images.nvidia.com/aem-dam/Solutions/geforce/ada/nvidia-ada-gpu-architecture.pdf
NVIDIA. (n.d.). Yun yu shuju zhongxin - NVIDIA Ampere jiagou [Cloud and data center - NVIDIA Ampere architecture]. https://www.nvidia.cn/data-center/ampere-architecture/
Shazeer, N. (2019). Fast transformer decoding: One write-head is all you need. arXiv. https://arxiv.org/abs/1911.02150
Su, J. (n.d.). Huancun yu xiaoguo de jixian lache: Cong MHA, MQA, GQA dao MLA [The extreme tug-of-war between cache and effect: From MHA, MQA, GQA to MLA]. Science Spaces. https://spaces.ac.cn/archives/10091
Sun, H. (2025, October 29). Why did M2 end up as a full attention model? MiniMax News. https://www.minimaxi.com/news/why-did-m2-end-up-as-a-full-attention-model
Wang, Z. (2025, October 9). HBM, xianjin fengzhuang he nengxiao de jidachengzhe [HBM, the master of advanced packaging and energy efficiency]. Tencent Cloud Developer Community. https://cloud.tencent.com/developer/article/2574378