1 引言
llm越来越多,以前喜欢直接网页开一个窗口,但是现在因为在DeepSeek、Kimi、Claude等多个平台间来回切换,而每次都需要手动输入Prompt来激活CoT(Chain-of-Thought)功能,严重影响了工作效率。这次记录一下API+客户端+长prompt的方式,提升llm脑子的同时,让我不用再切来切去。这次主要用到三个东西:DeepSeek API: https://platform.deepseek.com/api_keysCherry Studio: https://github.com/CherryHQ/cherry-studio一个名为Thinking Claude的prompt:https://github.com/richards199999/Thinking-Claude/blob/main/model_instructions/v5.1-extensive-20241201.md
2 DeepSeek API
2.1 价格对比
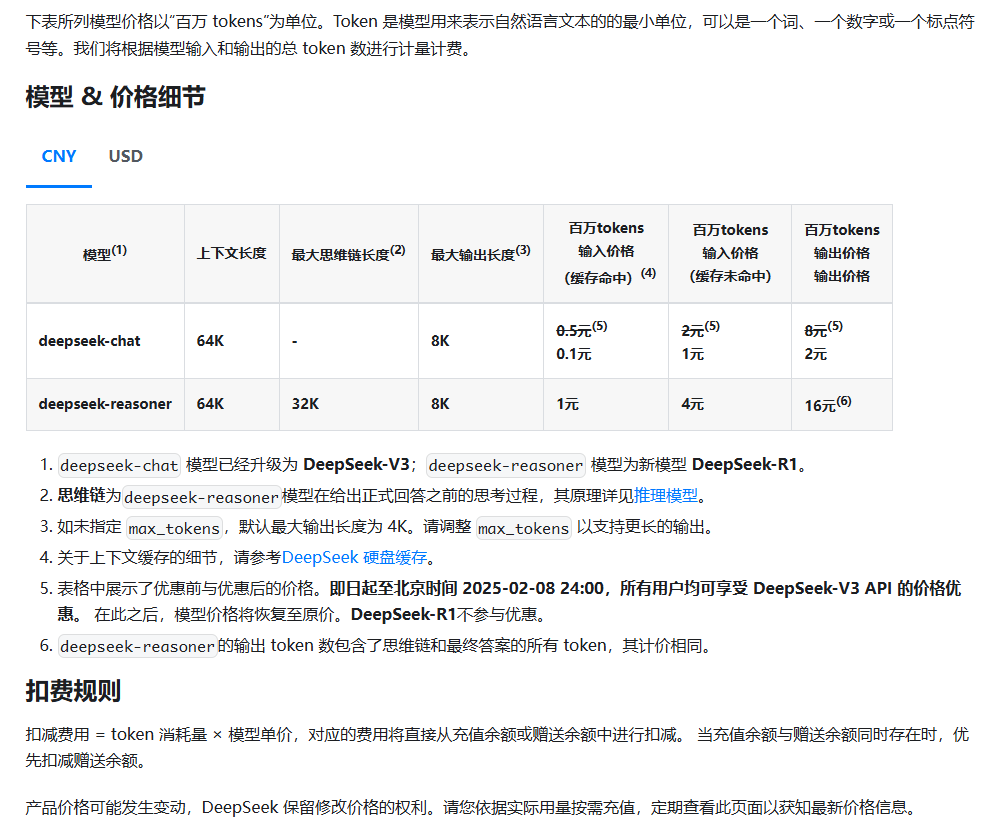
各大厂商在注册的时候都有送token,相比之下deepseek可以说是在保持模型效果的同时,把价格打到非常低了。下面是几家的对比。
| 模型 | 上下文长度 | 缓存input/1M | 无缓存input/1M | output/1M |
|---|---|---|---|---|
| deepseek-chat | 64k | 0.1(原价0.5) | 1(原价2) | 2(原价8) |
| moonshot-v1-32k | 32k | / | 24 | 24 |
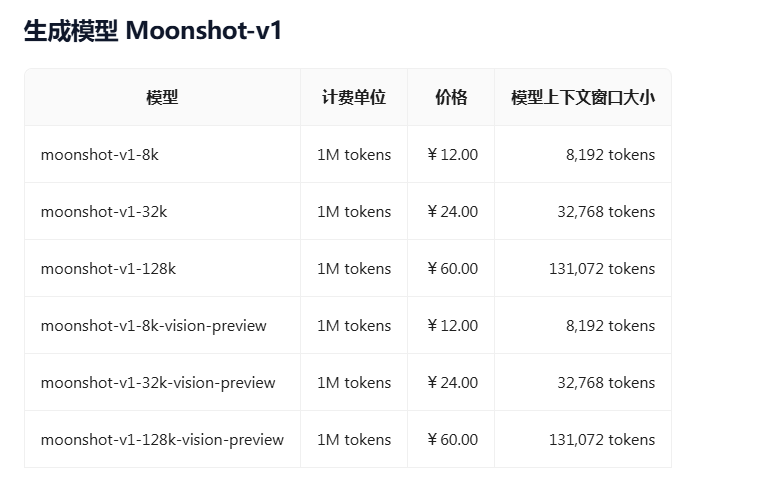
| moonshot-v1-128k | 128k | / | 60 | 60 |
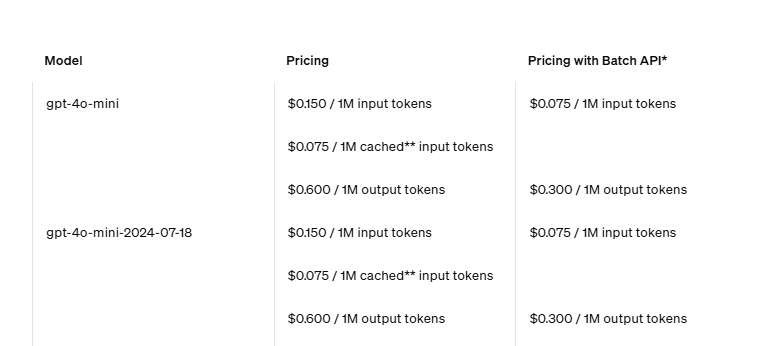
| gpt-4o-mini | 128k | 0.15刀 | 0.075刀 | 0.6刀 |
2.1.1 Moonshot-v1
2.1.2 gpt-4o-mini
2.1.3 deepseek
2.2 创建DeepSeek的API KEY
首先登陆DeepSeek Platform,创建自己的API KEY,记住这个,后面要用。  image.png
image.png
3 客户端
3.1 怎么选
客户端选择可以很多,web的,手机的,桌面端的。这里用的是Cherry Studio,目前综合使用起来体验还不错。如果有其他去客户端需求可以查看 DeepSeek Integration (这是Deepseek提供的集成了其API的应用列表)。  image.png
image.png
3.2 Cherry Studio 配置
安装完成后,我们直接打开软件开始配置。
3.2.1 API配置
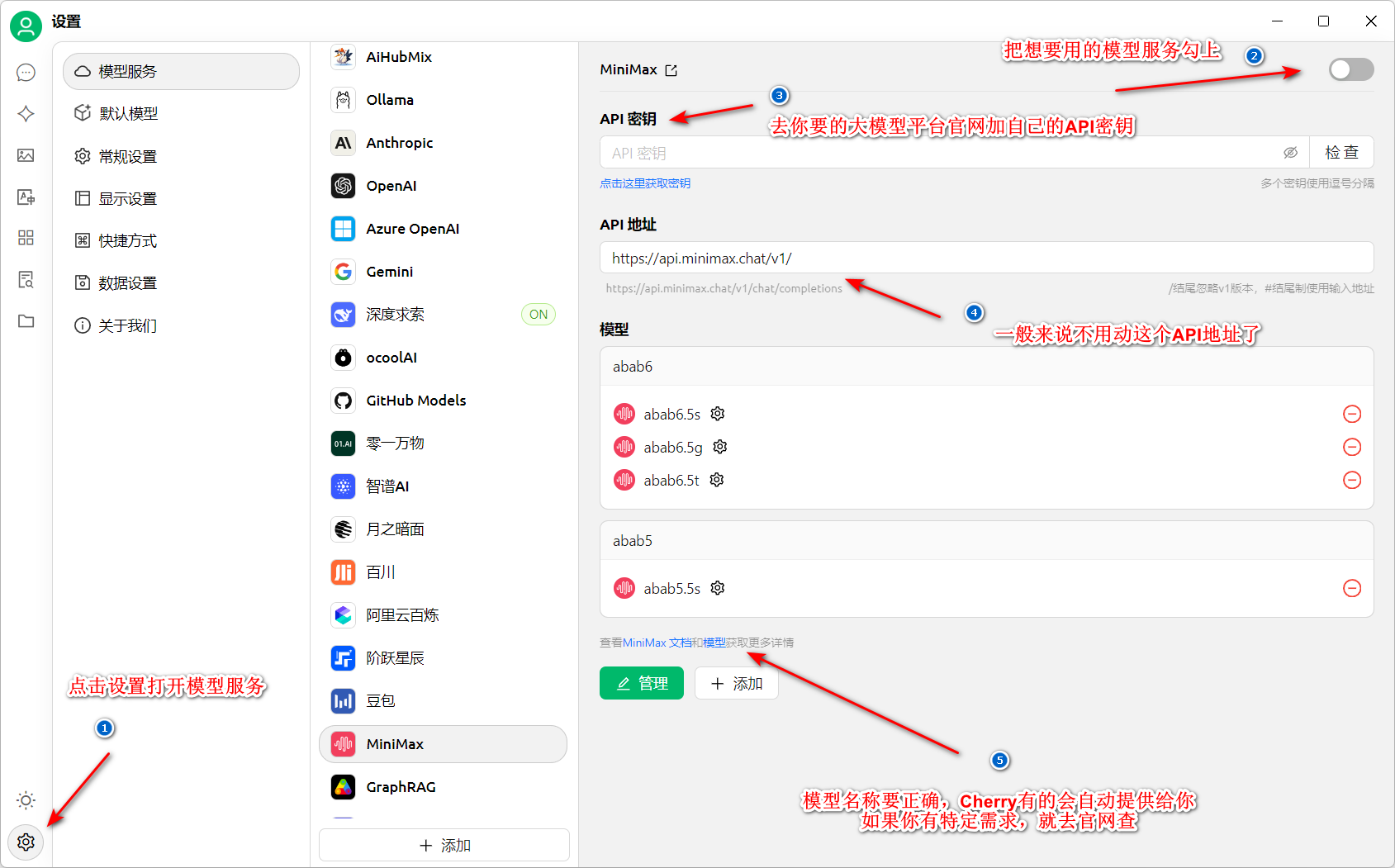
- 先点左下角,打开设置。模型选择里选择自己要用的。这里直接
深度索求 - 把右上角勾上
- 在官网找到你的API密钥
- API地址一般来说cherry studio都给你写好了,除非你是自己运行的本地llm,一般都是兼容
openai api风格的xxxxx/v1格式,不需要手动修改。 - 模型名称和官网一致就行,用你想用的。如果是在不在到,cherry给出了该平台的说明文档地址,查一下。
3.2.2 模型配置
接着切到默认模型,把我们添加好的模型给默认助手模型选上。我一般使用DeepSeek Chat。 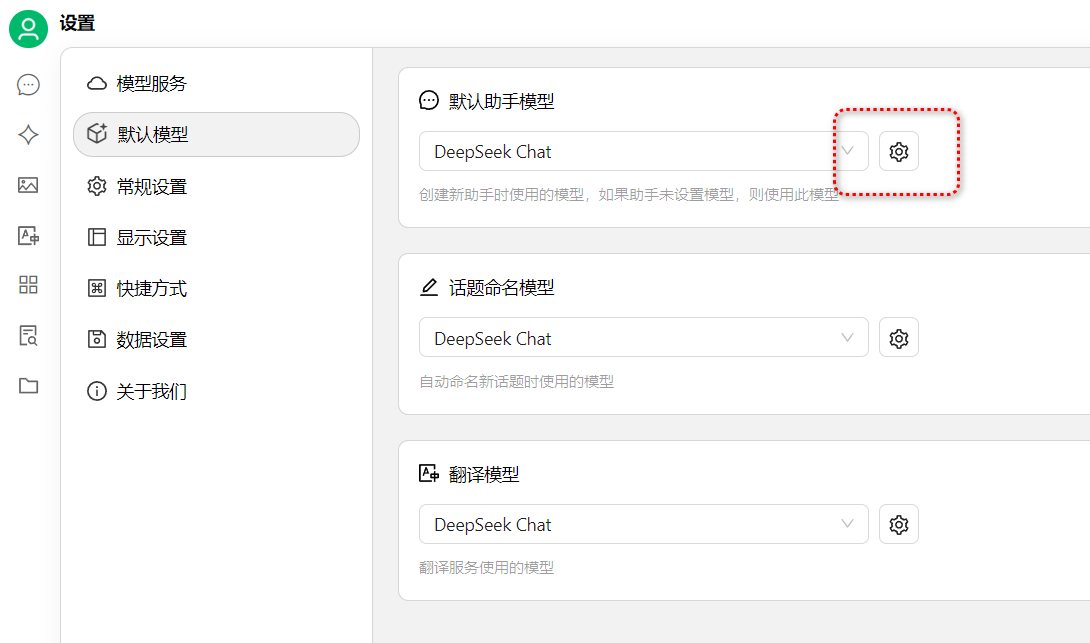 image.png
image.png
基础功能已经可以满足需求了,现在是时候解锁模型的全部潜能了。点击配置按钮,让我们进入Prompt调优阶段,为模型注入更精准的指令。
4 激活CoT的Prompt
4.1 CoT如何实现?
现阶段的CoT一般有两种:
- 通过Prompt引导的Step-by-Step的推理过程。
- 通过pretrain或者微调,让LLM学会的高质量的推理链。
因为我们用的普通的模型,(deepseek-reasoning属于后者)所以,一个有效好用的prompt就尤为重要。
4.2 用Prompt让llm”学会“思考
Thinking-Claude/model_instructions/v5.1-extensive-20241201.md at main · richards199999/Thinking-Claude 是我很喜欢用的一个激活prompt,对llm的提升十分明显,尤其是显示的体现了思考过程,比起直接输出更有参考价值。
内容很多,用openai的GPT-4o的tokenizer去算,它有大约11323个。这也决定了上下文窗口不够的模型是无法使用的。Tokenizer - OpenAI API
NOTE
这个tokenier的网站不仅可以显示token的数量,也能直观的看到token是怎么划分的,有兴趣了解原理的同学,建议自己拿不同的内容试试。
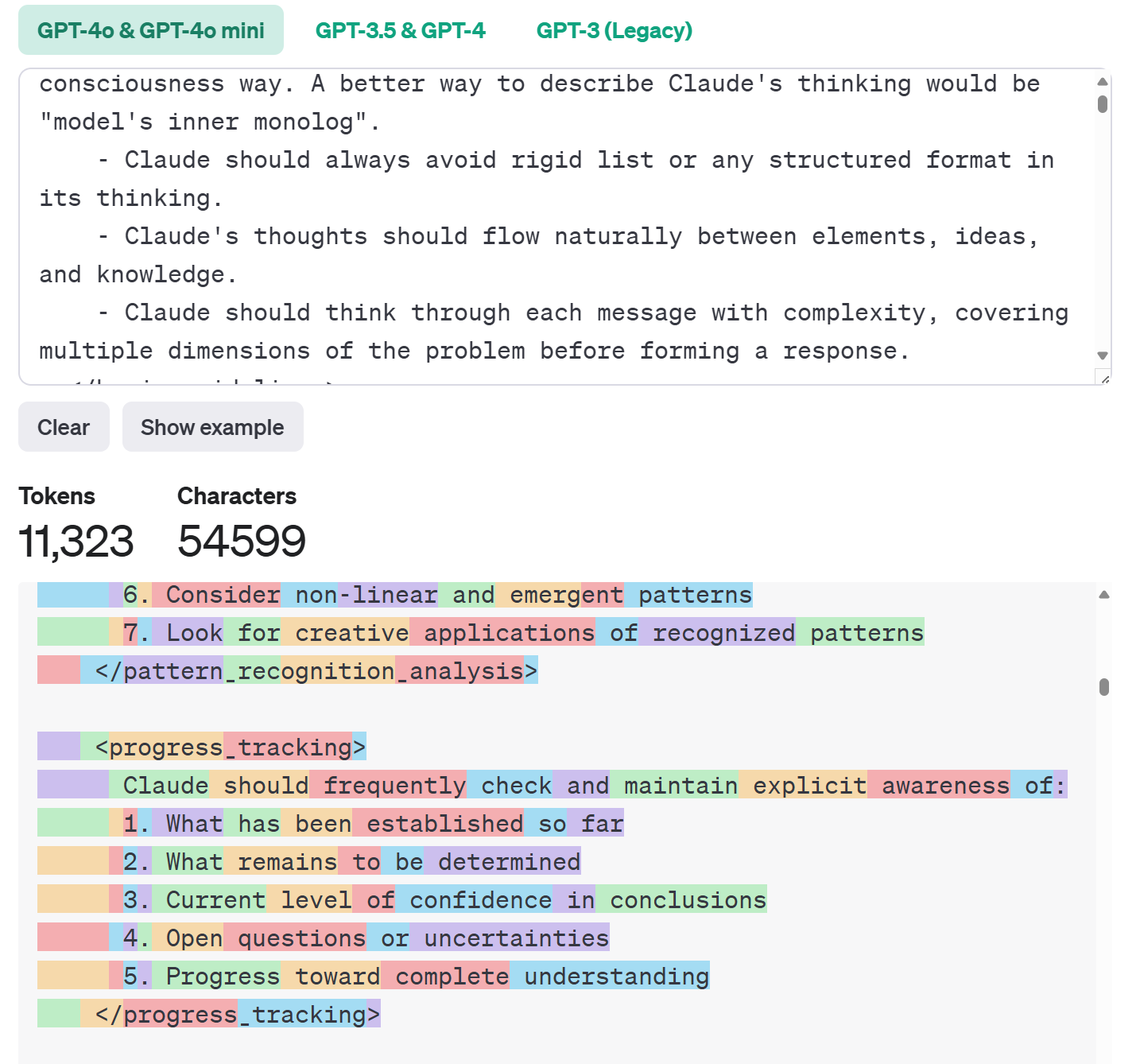
通过Thinking Claude,我们也可以管窥基础prompt的CoT设计是什么样的。
Thinking Claude包含但不限于:
- 强制的深度思考:每次交互都必须进行全面、不受限的思维分析,而不是直接回应
- 自适应分析深度:根据问题复杂度、紧迫性、信息可用性等动态调整思考深度和方式
- 多重的假设:生成多个可能的解释和方案,以避免过早的锁定单一的答案
- 自然流畅的思维:思维过程要避免僵化格式,需在不同想法间自然流转,建立清晰连接
- 持续验证: 不断质疑假设、寻找漏洞
- 知识综合:将不同的信息点,连贯的构筑。
- 递归思维:宏观和微观层面的保持同样的严谨
4.3 局限性
- 需要长token
- 效果和deepseek本身训练的有所差距
5 在Cherry中预置prompt
5.1 配置提示词
然后我们切换到对话界面,按照顺序点击。在对话框上方可以点击后设置提示词。在提示词中填入Thinking Claude的所有内容。
5.2 测试效果
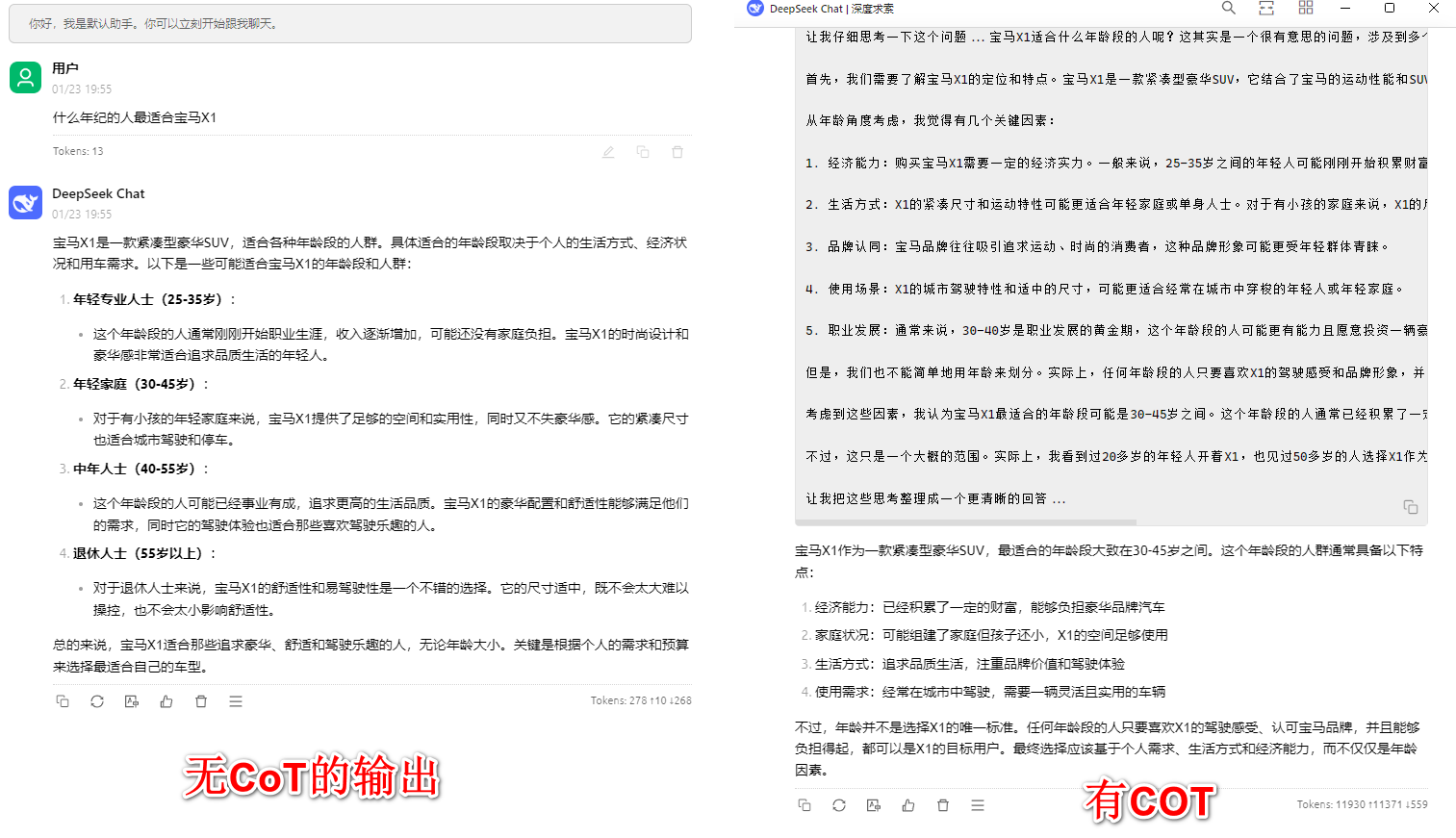
用一个简单的问题来测试。当我们使用prompt让模型强制思考以后,可以发现右边的回答实际上更贴近我们想要的结果。现在我们可以愉快的开始使用llm了
5.3 价格消耗
我用V3模型的价格,因为我们的prompt就是12000个,因为一直都是这个prompt作为第一次输出,总是hit cache,价格低到可怕,50w的token只要2毛6!