1 TL,DR;
把embedding放在基础原理靠后的地方,其实是我写这个系列一开始就想好的。毕竟有了其他模块的一些前置知识以后,可能才会对这些抽象、晦涩的东西感兴趣。
在这部分,我会说一下embedding的的概念,通过流形(Manifold)去从理论角度理解embedding layer,再通过实际的embedding model的运用。说明现代大模型中RAG的理论指导实践的具体体现。
2 词向量的发展历史
纵观词向量,其具有代表性的技术有:
One-Hot Encoding。这种方法简单地将每个词转化为一个漫长二进制向量中唯一的“1”,就像在只有“猫”、“狗”、“苹果”三个词的词典里,“猫”是 [1,0,0],“狗”是 [0,1,0]。它虽然让计算机能够编码词汇,但生成的向量既稀疏又毫无语义内涵,无法表达“猫和狗相似”这样基本的语义关系,仅仅是解决了符号到数字的映射问题。并且随着词表的增长,它会变得越来越庞大冗余。
Word2Vec 通过神经网络训练,将词汇压缩到低维稠密的连续向量空间中。“国王”与“女王”的向量距离会非常接近,甚至能通过“国王 - 男人 + 女人 ≈ 女王”这样的线性类比来展现其捕捉到的语义关系。然而,它的局限在于每个词仅有一个固定的向量,无法区分“苹果手机”和“吃的苹果”之间的含义差异。
BERT 能够根据词汇在句子中的不同上下文,动态地生成其向量表示。这意味着在“苹果发布了新手机”和“这个苹果真好吃”这两个句子中,“苹果”这个词会获得两个截然不同的向量,真正实现了对一词多义现象的理解。
LLM as Embedding Model 我们先按住不说,往后看。
3 Transformer中的Embedding Layer
我们通常说的embedding有两种,一个是embedding layer,也就是transformer架构中的一个层。另一个是embedding model,是一个独立用于将输入转为语义向量的模型。我们首先说说embedding layer。
回顾一下整个Transformer流程,在该架构下,我们用一个训练好的Tokenizer(分词器)将输入转为token,接着,我们将token转为token id。在推理阶段,Embedding Layer将这些token id转换为固定维度的向量。
模型内部维护一个巨大的嵌入矩阵(Embedding Matrix),其行数等于词汇表的大小,列数等于嵌入向量的维度。这个矩阵是模型的可训练参数,在训练开始前被一次性地随机初始化,之后通过反向传播不断学习和优化。对于输入的每一个token id,模型会从这个矩阵中精确地取出对应索引的那一行向量作为其初始表示。
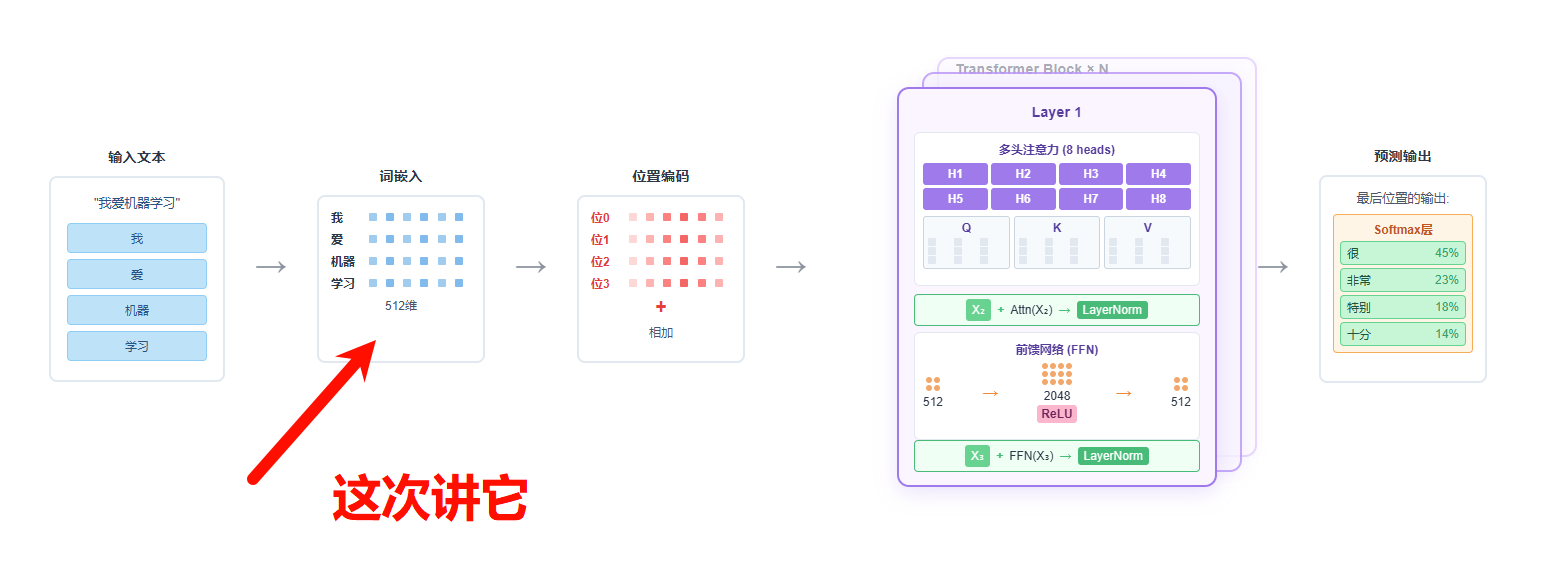 transformer架构下的embedding layer
transformer架构下的embedding layer
这个初始的嵌入向量,随后会连同位置编码一起,被送入Transformer的其他模块进行深层处理。在整个模型的训练过程中,梯度会反向传播至这个嵌入矩阵,不断调整其中每个词向量的值,最终学习到一个能够表达丰富语义信息的向量空间。
这个过程的核心思想,是用向量空间中的“位置”和“方向”来表示现实世界中的“意义”和“关系”。这听起来很抽象,还是那个经典的例子:
vector('国王') - vector('男性') + vector('女性') ≈ vector('女王')
如果到这为止,我们可以将embedding理解为向量化的一个方法。不过接下来,我们要说一些抽象的东西来进一步理解。
3.1 本质
从根本上说,Embedding是一种数学映射,它将离散的符号(如单词、商品ID、用户ID)转换成一个连续的、稠密的向量(一串固定长度的实数)。它不局限于NLP领域,现代环境下,图片,声音等其他模态的数据,也适用于embedding。
如果把embedding理解为向量化,那么为什么要叫它embedding,其翻译是词嵌入。而不直接交features或者vectors,反而用了这么一个词?
回到刚才那个国王和女王的例子。既然我们知道在高维空间下,方向和夹角可以表示一定的意义。
那么离国王更近的那堆向量都是什么意思?或者说这个空间下的所有向量,都有意义么?
如果每一个向量都有意义,比如我们在朴素的transformer架构下,我们embedding选择的维度是768。那么这个768维的欧几里得空间下的每一向量都是均匀分布的,都有意义?
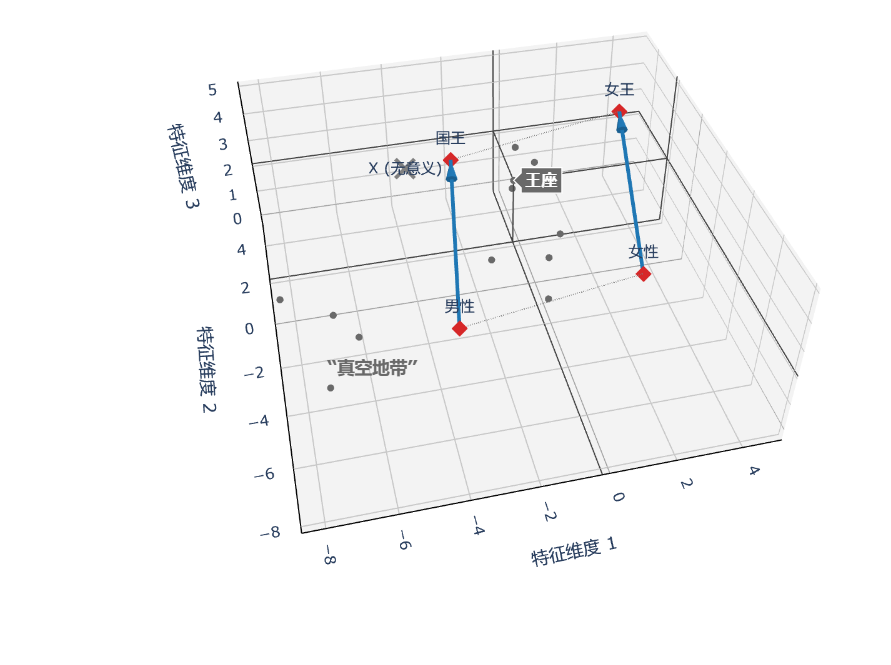
所以,一旦细细思考起来就发现了不对劲的地方了。所以,这个空间下的向量必然不是均匀分布。
于是我们有了机器学习领域非常重要的一个理论:流形假说
流形假说认为,我们现实世界中看似复杂无比的高维数据,比如人类语言构成的可能性空间,实际上并非杂乱无章地填充在整个高维空间里,而是高度结构化地分布在一个光滑的、内在维度低得多的几何结构,即“流形”上。我们把这个有意义的向量富集的区域,称为语义流形。
大名鼎鼎的克莱因瓶就是一个经典的流形,下面的几种情况都是流形或者流形的局部
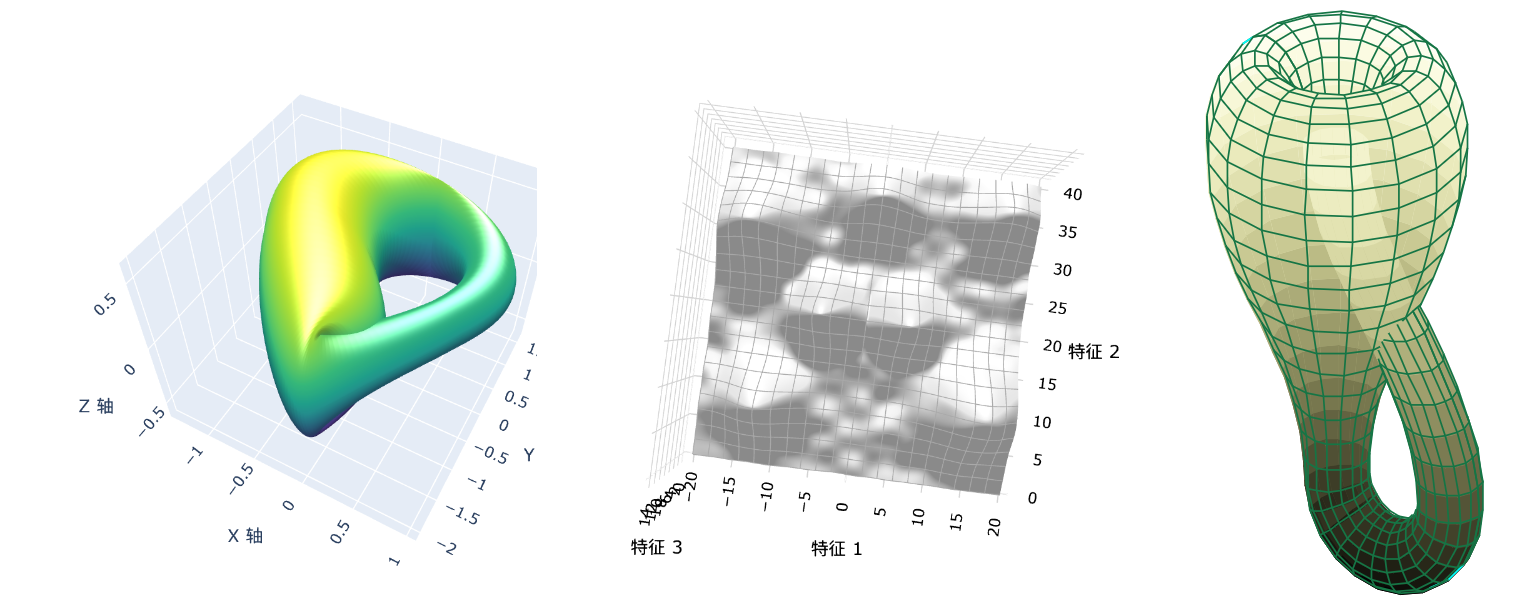
好,内容变得抽象起来了。那我们再看个经典形象的例子:
二维流形:在我们三维空间下,如果有一张皱皱巴巴的纸 ,这张纸肯定是二维的,但是它皱皱巴巴,他不是平整的占据一个二维的空间,而是需要通过三维空间,也就是长宽高,才能容下它。而我们还能把这张纸揉成一个近似圆形的形状。
这就像把一个二维的东西”嵌入“到三维空间中一样。

流形假说为我们理解嵌入提供了一个极其强大且直观的框架。基于这一假说,我们可以认为,一个训练良好的embedding模型所构建的语义空间,其有效数据的分布,通常会高度集中在一个近似于低维流形的结构上,而非均匀填满整个高维欧几里得空间。
这里,Embedding的含义与数学中流形的“嵌入”概念形成了呼应。前者指将符号植入向量空间,后者指将一个低维空间嵌入高维空间。这种概念上的契合,为我们提供了一个从几何视角深入理解Embedding。
所以流形有什么特性呢?
先看不怎么说人话的定义:
在数学中,流形是可以“局部欧几里得空间化”的一个拓扑空间,即在此拓扑空间中,每个点附近“局部类似于欧氏空间”。更精确地说,n维流形(n-manifold),简称n流形,是一个拓扑空间,其性质是每个点都有一个邻域,该邻域同胚于n维欧氏空间的一个开集。
对这个定义中出现的关键数学概念解释,有基础就跳过这些概念的部分吧。
3.2 拓扑空间
一个极度简化的空间描述,它不关心实际的距离、夹角等。我们只关心其连通性和邻近关系。最为直观的例子就是地铁线路。坐地铁的时候,站内的地铁信息都是一条直线,它只描述了两个事:1. 站和站之间的邻近关系。2. 站和站的连通性。至于两个站之间距离不一样,这之间可能会拐弯,它不描述也不关心。而当我们看全部的地图的时候,就能直到,只有换乘站是可以让你通联到其他线路的。你不能从1号线的独立的站,直接蹦到2号线的某一站。
所以当我们说拓扑空间时,其实是在表达:
- 连续性:一个函数/变换是不是“平滑”的?
- 极限:一个点序列是不是“趋近于”另一个点?
- 连通性:这个空间是不是一个整体,还是由几块不相干的部分组成的?
邻域:直觉上说,一个点的邻域是包含这个点的集合,并且该性质是外延的:你可以稍微“抖动”一下这个点而不离开这个集合。也就是说对于任意一个点,我们都可以找到它的的邻域,而这个邻域在流形的局部上来说,就是一个欧几里得空间。
同胚:这个词的中文翻译其实非常好,同一个胚子出来的。我们可以把他理解为一种变形,这种变形不是数学上的,可能不存在这样的公式。而是指想象上,我们可以通过一种不撕裂原有形状,不新增开口这两个限定条件下,对物体进行拉伸、压缩等形态变换操作。而无论怎么变,他们都是一样的,因为他们”同胚“
开集:通俗的说就是指这个空间自身没有“终点”或“断崖”。比如篮球,我们站在三维空间下看,它是一个圆球,有明显的边界。但是到那个经典的蚂蚁那个例子上,篮球上的蚂蚁无论上下左右怎么爬,都是在这个篮球上,它在篮球上一直走一直走,都也走不出篮球。也就说其边界要在更高维度的空间视角才能找到,而它本社那是无边的。
4 从流形特性理解embedding
上面干巴巴定义描述了流形的特性,我们一个个掰开说。
4.1 局部同胚欧几里得空间
流形最核心的特性之一,在于其局部与全局的差异与统一。无论全局的语义流形可能多么扭曲,流形假说认为,只要我们观察任何一个点足够小的邻域,它就近似于一个平坦的欧几里得空间。
这一特性为我们理解Embedding空间的行为提供了一个有力的几何视角。它与我们在训练好的词嵌入中观察到的现象高度一致: vector('King') - vector('Man') + vector('Woman') ≈ vector('Queen'),这种线性类比,之所以能够成立,是因为模型在学习过程中,成功地在局部区域内构建了近似线性的结构来表达这些关系。
流形的局部平坦性为这种局部线性结构的存在提供了一个数学模型。同样,我们广泛使用余弦相似度或欧氏距离来衡量词向量的“邻近度”,其有效性也依赖于这样一个假设:**在足够小的语义范围内,向量空间中的直线距离(弦距离)是流形上真实语义距离(测地线距离)的良好近似。**但必须注意,这种线性关系并非普遍成立,其有效性高度依赖于具体语境和关系类型。
但是,这种线性关系并非普遍成立,其有效性高度依赖于具体语境和关系类型。(至于为什么不是普遍成立,可以看这篇https://arxiv.org/abs/1606.07736)
4.2 拓扑空间、邻域带来的连续性和连通性
如果说局部欧几里得性是流形的“微观构造”,那么其拓扑性质——连续性与连通性——则决定了这些“微观贴片”如何融合成一个“宏观宇宙”。
连续性确保了流形是一个光滑的曲面,没有断裂和跳跃,这意味着语义的微小变化只会引起Embedding向量的微小移动。
而连通性则更进一步。尽管关于不同领域(如“法律术语”与“网络用于”)是否构成独立子流形存在讨论,但现代大型语言模型的构建,在实践中隐含了一个有成效的工作假设:所有可被语言描述的人类知识,最终可以在一个高维空间中被映射为一个宏观上单一、连通的流形。
这一假说的一个侧面佐证是,它为跨领域的知识迁移、隐喻的创造,乃至大语言模型的零样本推理能力提供了几何学基础,保证了整个语义空间是“可通达的”,而非由互不相干的“意义孤岛”构成。
4.3 嵌入和内在维度
最后,流形假说揭示了Embedding设计中最核心的权衡:我们为何要将一个内在维度并不高的语义结构,嵌入到一个维度极高的欧几里得空间中?
答案在于,这个高维的**环境空间(Ambient Space)并非语义本身所需,而是我们为保证“语义保真度”而人为设定的一个“计算舞台”。这就像我们无法把一张揉皱的纸(2D流形)完美地压到一条直线上(1D环境空间),但可以轻易地将它放置在三维空间(3D环境空间)中。因此,当前Embedding的高维设定,是在计算效率与表达丰富性之间取得平衡,它是为保证模型有足够“自由度”将复杂流形无冲突地“展开”而付出的必要“计算成本”。
4.4 流形特性的总结
在训练多个垂直领域(垂类)文本的大模型时,模型学习到的嵌入空间对应一个连续的低维流形。这个流形不是孤立的碎片,而是一个连贯的整体,但其中包含多个语义簇,每个簇对应一个垂类的核心概念。这些簇之间通过共享词汇、抽象语义或上下文关系相互连接,形成平滑的过渡区域。例如,医疗领域的“操作”和科技领域的“操作”可能在不同簇中,但通过通用含义连接。这种连续性使模型能够处理跨领域任务,而簇的存在反映了领域特异性。流形的具体几何结构,取决于训练数据的多样性和模型架构。
在这个图中,我们可以把每个小山峰都理解为一个垂类领域,哪些低洼地带依然是不平整的,他们是语义稀薄的区域,但是没有断裂,而多个山丘就组成了语义簇,这个语义簇可能也就是我们语义流形的一个局部而已:
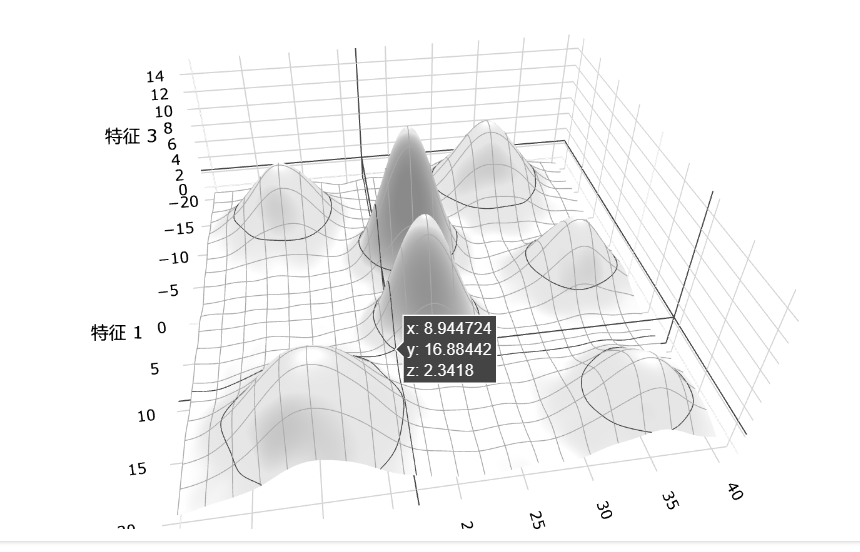
现在,通过降维可视化,我们不再把embedding看做向量化了。我们可以给Embedding一个更精确的定义:它是学习一个映射函数的过程,该函数将高维、稀疏或离散的输入,投影到由一个潜在的、内在维度相对较低的连续流形所构成的向量表示空间中。
这也就非常符合Transformer架构下的实践:我们首先设定一个足够高维度的欧几里得空间(例如768维或者更高)作为“容器”,然后通过模型训练,学习到一个能将输入数据“展开”并安置在这个内在流形上的最优映射。
回到那个皱巴巴的纸的例子:在机器学习中,我们并没有那张现成的纸。我们拥有的,是散落于三维空间中的一堆点(我们的训练数据)。我们的任务,就是通过学习一个变换,来发现并参数化这些数据点内在的二维结构,从而重构这张皱巴巴的纸。
这个学习过程,本质上是在发现数据的内在低维结构。因此,从概念层面看,Embedding是一种高度复杂的表示学习,它通过发现数据内在的几何结构,实现了一种有意义的“降维”,将语义可能性,压缩到了一个有限但结构丰富的低维流形之上。
5 说了那么多,还不是当做向量化就够了?

确实,这很难反驳。因为在日常应用层面,比如构建一个简单的RAG系统,将Embedding理解为“一个能用余弦相似度衡量语义的向量”已经完全足够指导我们完成工作了。我们不需要在写代码时去计算流形的曲率。
但是,我们能理解清楚embedding的本质,在遇到更复杂的问题,尤其是关于模型效率、泛化能力、微调效果和数据质量时,“语义流形”这个抽象的概念,就变成了极具价值的工程指导思想。
好,你说你只要训就完事了,RAG的时候,把预料丢给embedding模型就好了。那我又要问出那句话了。
你怎么证明你的训练在你说的垂类领域有提升的?你又怎么证明你的chunk划分是合理的?
这些问题是不管是工作还是搞科研,还是你单纯爱学习都不可避免的。所以我们接下来从流形视角看看大模型几个常见问题。
为什么当我们使用LoRA微调的时候,只需要一些高质量的数据,这个量级非常小了?
大部分人做LoRA微调,都能大概说明白LoRA的逻辑:它通过在原有权重旁边增加一个低秩的“旁路”来进行微调,只训练这个小旁路,所以又快又省。
那么凭什么一个小旁路就帮我们解决了问题?
从Embedding和流形角度就是,基础大模型通过海量数据,已经学习到了一个覆盖人类通用知识的、极其稳健的语义流形。当我们用一个垂类的高质量数据进行微调时,我们并不是要从零开始学习一个新的流形。我们的目标仅仅是对某个特定区域,比如“法律”或“医疗”领域,进行一次平滑的、局部的“塑形”或“扭曲”。
LoRA的低秩更新,在几何上恰好对应着这种低维度的、结构化的“塑形”操作。高质量数据提供了清晰、一致的梯度方向,确保了这种“塑形”是精准有效的;而低质量数据则会产生杂乱、高维的更新需求,超出了LoRA低秩假设的能力范围。
这个过程中,我们可能需要让“合同违约”这个点更靠近“赔偿责任”,或者在医疗领域细化出“靶向治疗”和“免疫治疗”这两个新的、紧密相连的子区域。当然模型的其他方面可能也会对此有帮助,比如tokenizer对垂类领域的token压缩能力等。我们可以通过多种方式去做到这个事,但是流形,是一个很好的角度去理解为什么LoRA可以有效,为什么高质量数据集能有效。
当我们量化一个原本是fp32的模型到int4以后,为什么它依然在某些任务上效果不错?
从精度本身来看,模型的成功量化首先归功于其内在的容错性。现代深度学习模型通常是高度过参数化 的,其庞大的参数量带来了巨大的冗余。这种冗余性使得模型对单个权重的精度扰动不那么敏感,具备了天生的容错能力。
另一方面,训练好的模型权重并非随机分布,而是呈现出一种高度集中的非均匀形态,绝大多数权重都聚集在零点附近。智能的量化算法正是利用了这一特性,它们并非粗暴地压缩整个FP32的理论范围,而是精准地找到权重实际分布的动态范围,并在此范围内进行更有效的映射。虽然权重的绝对值被近似了,但它们之间至关重要的相对大小关系得以最大限度地保留。
从词嵌入和流形的角度来看, 我们可以将这一现象理解为:量化操作相当于对定义流形表面的权重坐标进行了离散化和近似。其效果并不会“撕裂”流形或改变其宏观的拓扑结构,比如连通性、区域划分,而仅仅是在其光滑表面引入微小的“褶皱”或“抖动”。由于模型的决策能力主要依赖于流形的整体形状、不同语义簇的相对位置关系,而非坐标的绝对精度,只要量化带来的扰动不足以破坏这种宏观的几何结构,模型的宏观语义理解能力就能得以保持。因此,流形的不变性为模型量化后的性能鲁棒性(我真的很不爱说这个词),提供了一个高度自洽的几何解释。
我还是觉得很抽象,能不能从工程角度说说?
6 Embedding Model and RAG
Embedding是RAG的基础组成部分,一般刚刚接触的时候,可以理解为把向量搜索就是计算查询(Query)和文档库(Corpus)中每个文档的Embedding,然后通过余弦相似度找到最“近”的几个向量,因为距离近代表语义相似。
余弦相似度就够了吗?
其实大家都知道余弦相似度肯定不够,检索出来的结果总是不那么理想。可是为什么呢?既然我们已经知道了embedding的抽象概念。我们来看一下在流形上 相似度 的计算方式。
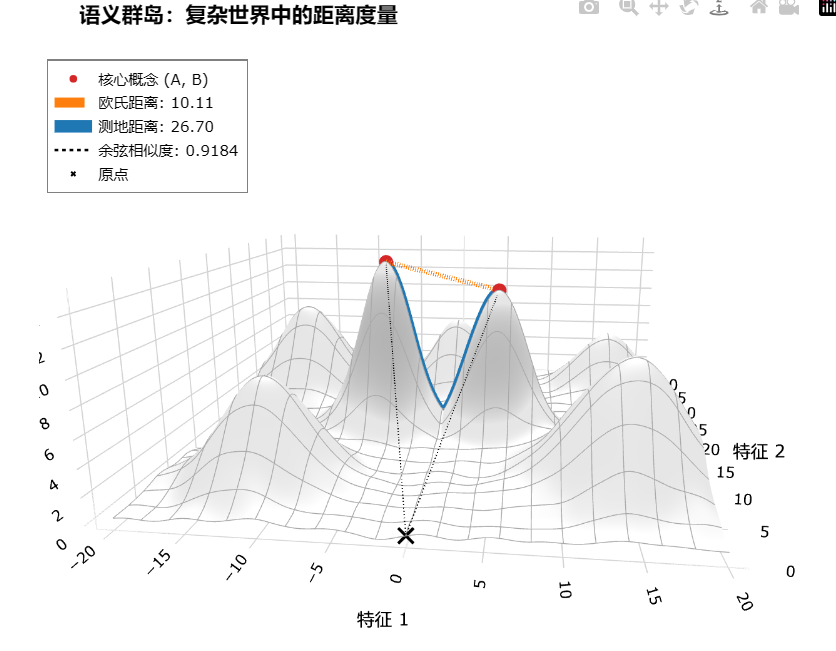
在这个语义流形上,我们看三个距离:欧式距离、测地距离和余弦相似度。
从高维环境空间的视角来看,我们可以直接“跨过”山体,拉一条直线连接它们。这条直线距离就是欧式距离。
如果我们站在原点观察,可能会发现这两座山峰恰好在接近的方向上,它们的向量夹角很小。这个夹角就是余弦相似度的体现。
在这两种度量下,这两个点都可能显得“惊人地接近”。但这种接近是一种具有欺骗性的几何幻象。因为在语义流型下,我们无法穿越那片由“无意义”的向量构成的空间。要从一座山峰走到另一座,我们必须沿着山脊下山,穿过山谷,再攀上另一座山。这条沿着流形表面的最短路径(蓝色部分),才是衡量真实语义距离的标准,我们称为测地距离。
这是向量搜索的核心困境。当我们输入一个查询,模型将其“嵌入”到这个流形上的一个点。理论上,最完美的搜索是找到与这个点测地距离最近的文档块。但实际上,在数以百万计的向量中计算测地距离是计算上不可行的。因此,我们今天所有的向量搜索,无论是基于余弦相似度还是欧氏距离,本质上都是对真实测地距离的一次计算上廉价的、但有风险的近似估算。
那么我们该如何应对这种“近似风险”?
这个近似之所以在大多数时候有效,是因为流形的局部具有欧式空间特性,在相对平坦的流形区域内,直线距离可以很好地近似曲线距离。然而,当两个概念在语义上相关,但在训练数据中很少共同出现的时候,比如一个专业的法律术语和一个日常生活的比喻,它们在流形上的“路径”可能很长且曲折。这时候搜索出来的结果就可能不是我们想要的。
所以,工程上的优化正是为了创造让这种近似更可能有效的条件。我们并非试图取代余弦相似度,而是在检索流程的各个阶段对其进行“扬长避短”。
RAG的精准度我们可以分为三个阶段,检索前优化、检索中优化和检索后优化。我们挑其中比较有代表性的说,通过这几个方案,是可以在工程上把这个估算方式失效的情况给进一步减少,甚至解决。
6.1 分块优化策略
分块优化策略属于检索前的优化,这个方案并没有直接解决上面说的部分场景下,近似估算可能失效的弊端,但是大部分情况下,这依然是这个场景下的较好的一个解法。
一个向量是对一块文本的几何抽象。如果这块文本内容庞杂,其生成的向量就会落在流形上的一个语义模糊区域,使得任何基于它的距离计算都变得不可靠。因此,高质量分块的目标,是确保每个文本块都对应流形上一个语义内聚的局部区域。在这样的区域内,“局部即欧氏”的特性更显著,我们的近似估算也更为可靠。
- 固定大小分块(Fixed-size Chunking) :作为一种简单的基线方法,我们设定一个固定值,比如300,当计算tokne到这个值的时候,就粗暴的分一个块。这个做法的弊端就是斩断了语义之间的关联,句子都没说完呢,截断了。当然,在某些快速验证的场景下,我们依然可以选择它。
- 递归分块(Recursive Chunking) 则智能一些,它尝试沿着文档的章节、段落等“自然边界”进行切割,比如我们按句号,按逗号,通过一些规则来指导分块。不过问题还是一样,我说完这句话,还想接着说,但是分块了,实际就是把有关联的依然分开了。
- 语义分块(Semantic Chunking) 则是流形思想最直接的体现。它不直接计算测地距离,而是通过计算相邻句子嵌入向量间的余弦相似度,来近似地判断它们在流形上的邻近关系,直到遇到一个“语义悬崖”,这代表着相似度的图片,才进行切分。
在语义分块中,我们利用局部的、细粒度的相似度判断,来构建宏观上语义连贯的文本块。它并没有解决余弦相似度在“跨越山谷”时的根本缺陷,但它通过精细化的预处理,极大地增加了我们的查询向量和文档向量落入同一个“平坦山坡”而非分属两座山峰的可能性,从而显著提升了后续检索的精准度。
但是记住,分块策略的效果受嵌入模型质量制约,不能把它当作万能的解决方案。
6.1.1 手动实现一个代码分块
class SemanticChunker:
"""
Qwen/Qwen3-Embedding-0.6B 模型实现语义分块的类。
"""
def __init__(self, model_name='Qwen/Qwen3-Embedding-0.6B', device=None):
"""
初始化分块器,加载模型和依赖。
:param model_name: huggingface模型名称。这里用的是Qwen3-Embedding-0.6B。
:param device: "cuda"、"cpu"或者None。
"""
# --- 初始化模型 ---
if device is None:
self.device = "cuda" if torch.cuda.is_available() else "cpu"
else:
self.device = device
# 启用 flash_attention_2
# self.model = SentenceTransformer(
# model_name,
# model_kwargs={"attn_implementation": "flash_attention_2"},
# device=self.device
# )
# cpu运行
self.model = SentenceTransformer(model_name, device=self.device)
print(f"Embedding model '{model_name}' loaded on {self.device}")
# --- 初始化NLTK句子分词器 ---
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
print("Downloading NLTK 'punkt' model for sentence tokenization...")
nltk.download('punkt')
def _cosine_similarity(self, v1: np.ndarray, v2: np.ndarray) -> float:
"""计算两个numpy向量的余弦相似度"""
dot_product = np.dot(v1, v2)
norm_v1 = np.linalg.norm(v1)
norm_v2 = np.linalg.norm(v2)
if norm_v1 == 0 or norm_v2 == 0:
return 0.0
return dot_product / (norm_v1 * norm_v2)
def chunk(self, text: str, percentile_threshold: float = 0.2):
"""
对输入的文本执行语义分块。
:param text: 需要分块的长文本。
:param percentile_threshold: 用于决定断点的相似度百分位阈值。
例如0.2代表使用所有相邻句子相似度中最低的20%作为切分标准。
:return: 一个包含文本块(字符串)的列表。
"""
# 步骤 1: 切分为句子
text = re.sub(r'([。!?])([^”’])', r"\1\n\2", text)
text = re.sub(r'(\.{6})([^”’])', r"\1\n\2", text)
text = re.sub(r'(\…{2})([^”’])', r"\1\n\2", text)
text = re.sub(r'([。!?\n\?])([”’])', r'\1\n\2', text)
sentences = [s.strip() for s in text.split('\n') if s.strip()]
if len(sentences) <= 1:
return sentences
# 步骤 2: 向量化,Qwen3-Embedding处理文档/句子时无需添加指令(prompt)
embeddings = self.model.encode(sentences, convert_to_numpy=True, device=self.device)
# 3: 计算相邻句子的相似度
similarities = [
self._cosine_similarity(embeddings[i], embeddings[i+1])
for i in range(len(embeddings) - 1)
]
# 步骤 4: 识别语义断点
if not similarities:
return [" ".join(sentences)]
breakpoint_similarity_threshold = np.percentile(similarities, percentile_threshold * 100)
breakpoint_indices = [i for i, sim in enumerate(similarities) if sim < breakpoint_similarity_threshold]
# 步骤 5: 组合成块(根据断点合并句子)
chunks = []
current_chunk_start_index = 0
for breakpoint_index in breakpoint_indices:
chunk_end_index = breakpoint_index + 1
chunk_sentences = sentences[current_chunk_start_index:chunk_end_index]
chunks.append(" ".join(chunk_sentences))
current_chunk_start_index = chunk_end_index
last_chunk_sentences = sentences[current_chunk_start_index:]
if last_chunk_sentences:
chunks.append(" ".join(last_chunk_sentences))
return chunks
if __name__ == '__main__':
# 示例长文本
sample_text = """
可再生能源是未来的发展方向。太阳能和风能作为其中的佼佼者,近年来技术取得了长足的进步。光伏板的转换效率不断提升,成本也在持续下降,使得分布式光伏发电在城市和乡村都得到了广泛应用。风力发电则在大规模电网接入方面展现出巨大潜力,尤其是在海上风电场项目上,全球各国都在加大投资。这些清洁能源的利用,对于减少碳排放、应对全球气候变化至关重要。
然而,可再生能源的普及也面临着严峻的挑战,其中最主要的就是储能问题。由于太阳能和风能具有间歇性和不稳定性,如何将高峰期产生的多余电能储存起来,在低谷期稳定输出,成为了电网安全的关键。目前的储能技术主要依赖锂离子电池,但其成本高昂、寿命有限,并且存在安全隐患。寻找更高效、更经济、更安全的储能方案,如液流电池、压缩空气储能等,是当前科研领域的热点。
为了推动整个绿色能源产业的发展,各国政府的政策支持同样不可或缺。从提供补贴、税收优惠,到建立碳交易市场,再到制定长期的能源转型路线图,宏观政策为市场设定了明确的预期。例如,欧盟的“绿色新政”和中国的“双碳”目标,都为可再生能源和储能技术的发展提供了强大的政策驱动力。这些政策不仅加速了技术创新,也引导了大量社会资本进入该领域,形成了良性循环。
"""
print("Initializing Semantic Chunker with 'Qwen/Qwen3-Embedding-0.6B'...")
chunker = SemanticChunker(model_name='Qwen/Qwen3-Embedding-0.6B')
# 使用 20% 的百分位作为断点阈值。对于主题转换明显的文本,调整 percentile_threshold 来观察分块结果的变化。
semantic_chunks = chunker.chunk(sample_text, percentile_threshold=0.3)
print("\n" + "="*50)
print(" Qwen3-Embedding-0.6B 语义分块结果")
print("="*50)
for i, chunk in enumerate(semantic_chunks):
print(f"--- Chunk {i+1} ---\n{chunk}\n")得到的结果是:
--- Chunk 1 ---
可再生能源是未来的发展方向。 太阳能和风能作为其中的佼佼者,近年来技术取得了长足的进步。 光伏板的转换效率不断提升,成本也在持续下降,使得分布式光伏发电在城市和乡村都得到了广泛应用。
--- Chunk 2 ---
风力发电则在大规模电网接入方面展现出巨大潜力,尤其是在海上风电场项目上,全球各国都在加大投资。
--- Chunk 3 ---
这些清洁能源的利用,对于减少碳排放、应对全球气候变化至关重要。
--- Chunk 4 ---
然而,可再生能源的普及也面临着严峻的挑战,其中最主要的就是储能问题。 由于太阳能和风能具有间歇性和不稳定性,如何将高峰期产生的多余电能储存起来,在低谷期稳定输出,成为了电网安全的关键。 目前的储能技术主要依赖锂离子电池,但其成本高昂、寿命有限,并且存在安全隐患。 寻找更高效、更经济、更安全的储能方案,如液流电池、压缩空气储能等,是当前科研领域的热点。
--- Chunk 5 ---
为了推动整个绿色能源产业的发展,各国政府的政策支持同样不可或缺。 从提供补贴、税收优惠,到建立碳交易市场,再到制定长期的能源转型路线图,宏观政策为市场设定了明确的预期。 例如,欧盟的“绿色新政”和中国的“双碳”目标,都为可再生能源和储能技术的发展提供了强大的政策驱动力。 这些政策不仅加速了技术创新,也引导了大量社会资本进入该领域,形成了良性循环。6.2 混合搜索策略
我们假设上面那个两个山峰的例子是:
代表“22年宝马X1价格”的A点和代表“23年奔驰C级评测”的B点,可能因为共享“年份+品牌+型号+评价”这类高级概念,导致它们的向量在原点看来方向很接近,也就是余弦相似度高,而且直线距离也近。可以说是一种几何幻象。
混合搜索引入了除了余弦相似度之外的搜索工具:词法搜索和元数据过滤。这两种工具不像向量搜索那样依赖相对的“方向感”,而是依赖“绝对地名”和“属性坐标”。属于一种偏刚性的策略。
- BM25:是elasticsearch自带的一种算法,langchain也有对它的支持。它也是一种基于词频、文档长度、文档频率等要素计算,有点类似TF/IDF。这里不过度展开,总而言之它是一种不同于余弦相似度的算法。具体可以查阅ES官方文档: practical-bm25-part-2-the-bm25-algorithm-and-its-variables
- 元数据过滤 (Metadata Filtering):元数据就是一个结构化的json,它针对我们不同场景下的chunk或者document进行了一系列描述,如果我们的文档块都带有
{'year': 2022, 'brand': 'BMW'}这样的元数据标签,那么过滤操作就相当于在流形上制定了2022和BMW的区域,这个区域可能是个局部欧式空间,也可能是一个子流形。但不管怎么样,我们选中的区域被大范围缩小了。
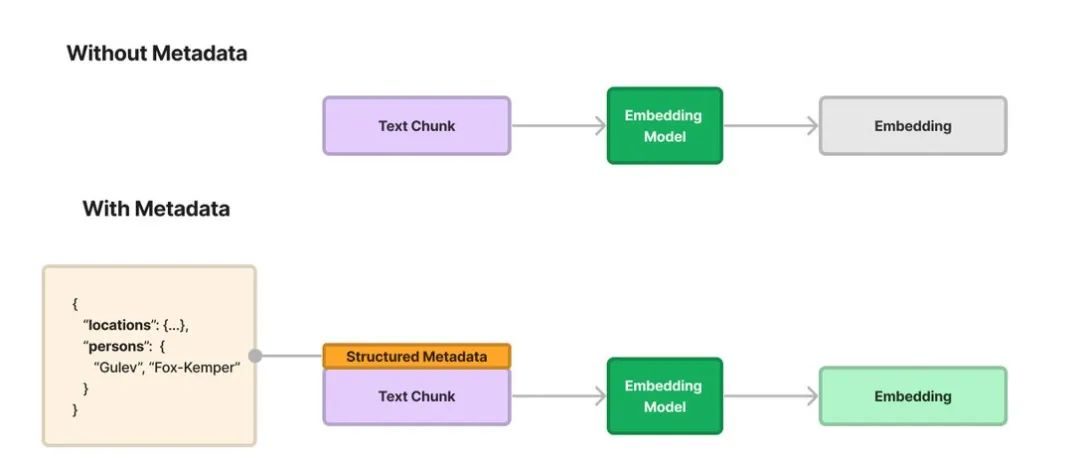
换句话说,即使都是选中top-k个chunk,通过混合检索的top-k个结果其命中我们想要的片段的概率大大提升了。现在当用户搜索“22年宝马X1价格”时,我们就会刚性的在语义空间中找包含“X1”的内容,而抽象的更高级的概念,比如“奔驰“,无论看起来多么“近”,都应该被排除。
6.3 交叉编码器(Cross-Encoder)和重排(Reranking)
现在,已经有了“分块优化”准备的高质量的语义单元,并通过“混合搜索”在语义群岛中快速召回了一批相关的候选文档。然而,混合搜索本质上是一个召回阶段,它的首要任务是快和全,确保潜在的正确答案包含在这份几十个文档的候选名单中。
作为检索后的阶段,重排之所以能够显著提升精度,其根本原因在于它采用了与初级检索不同的模型架构。
以 Qwen3-Reranker-0.6B。该模型将查询(Query)与一个候选文档(Document)拼接成一个统一的序列, [CLS] Query [SEP] Document [SEP],并整体输入至预训练语言模型中进行联合编码。通过 Transformer 架构中的自注意力机制,模型能够对查询和文档中所有token之间进行深度的双向交互建模,从而捕捉更复杂的语义关联。
不同于双编码器,比如BAAI/bge-large-zh-v1.5,仅依赖向量相似度比较,交叉编码器直接对查询-文档对进行联合语义推理,最终输出一个标量分数作为相关性衡量。现阶段,普遍认为这种深度融合的判断方式使其在语义匹配精度上显著优于双编码器模型。
为了不过度展开这个阶段,我们直接拿例子来说说。
当问 “新款宝马X1的隔音效果怎么样,尤其是在高速行驶时?”,召回的结果中可能有我们想要的答案,不过也可能答案不够接近我们想要的。举例来说:
- “关于新款宝马X1的隔音效果,尤其是在高速行驶时怎么样,这是很多车主都非常关心的一个问题,也是衡量车辆高级感的重要指标。”
- “上周末我开着新提的X1跑了一趟长途。动力方面1.5T在市区绝对够用,但上了高速后段加速会有点乏力。不过让我惊喜的是,即便时速超过120公里,车内的风噪和胎噪控制得相当不错,比我预想中要安静很多,这得益于前排的双层夹胶玻璃。”
第一句话提到了我们问题的关键词,但是后面真的回答了我们问题吗?明显是一种车轱辘话。再看第二句话,虽然句式上没有贴合问题,起手先装了一下“新提的”,但是后面的内容其实是更接近我们想要的问题的。
我们用reranker跑一下看看。
6.3.1 bge-large-zh-v1.5 比较 qwen3-reranker
from sentence_transformers import SentenceTransformer, CrossEncoder
import numpy as np
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"使用的设备: {device}")
query = "新款宝马X1的隔音效果怎么样,尤其是在高速行驶时?"
documents = [
"关于新款宝马X1的隔音效果,尤其是在高速行驶时怎么样,这是很多车主都非常关心的一个问题,也是衡量车辆高级感的重要指标。",
"上周末我开着新提的X1跑了一趟长途。动力方面1.5T在市区绝对够用,但上了高速后段加速会有点乏力。不过让我惊喜的是,即便时速超过120公里,车内的风噪和胎噪控制得相当不错,比我预想中要安静很多,这得益于前排的双层夹胶玻璃。",
"新款宝马X1的座椅舒适度做得很好,长途驾驶也不容易累,而且它的悬挂调校在保证支撑性的同时也兼顾了日常行驶的舒适性。",
"你知道X1哥吗?好像是个少爷",
"宝马X1的油耗表现相当经济,百公里综合油耗仅为7升左右。"
]
print("\n--- 初始化模型 ---")
bi_encoder = SentenceTransformer('BAAI/bge-large-zh-v1.5', device=device)
cross_encoder = CrossEncoder('Qwen/Qwen3-Reranker-0.6B', trust_remote_code=True, max_length=512, device=device)
print("双编码器和交叉编码器模型加载完毕。")
print("\n" + "="*50)
print(" bge-large-zh-v1.5排序")
print("="*50)
query_embedding = bi_encoder.encode(query, normalize_embeddings=True, convert_to_numpy=True)
doc_embeddings = bi_encoder.encode(documents, normalize_embeddings=True, convert_to_numpy=True)
cos_scores = (query_embedding @ doc_embeddings.T)
docs_with_id = [f"Doc {i+1}: {doc}" for i, doc in enumerate(documents)]
bi_encoder_results = sorted(zip(cos_scores, docs_with_id), key=lambda x: x[0], reverse=True)
for score, doc in bi_encoder_results:
print(f"Score: {score:.4f}\t{doc}")
print("\n" + "="*50)
print("Qwen3-Reranker-0.6B 重排结果")
print("="*50)
model_inputs = [[query, doc] for doc in documents]
cross_scores = cross_encoder.predict(model_inputs, show_progress_bar=True, batch_size=1)
reranked_results = sorted(zip(cross_scores, docs_with_id), key=lambda x: x[0], reverse=True)
for score, doc in reranked_results:
print(f"Score: {score:<10.4f}\t{doc}")我们看一下计算的结果:
==================================================
bge-large-zh-v1.5排序
==================================================
Score: 0.8226 Doc 1: 关于新款宝马X1的隔音效果,尤其是在高速行驶时怎么样,这是很多车主都非常关心的一个问题,也是衡量车辆高级感的重要指标。
Score: 0.6805 Doc 2: 上周末我开着新提的X1跑了一趟长途。动力方面1.5T在市区绝对够用,但上了高速后段加速会有点乏力。不过让我惊喜的是,即便时速超过120公里,车内的风噪和胎噪控制得相当不错,比我预想中要安静很多,这得益于前排的双层夹胶玻璃。
Score: 0.6434 Doc 3: 新款宝马X1的座椅舒适度做得很好,长途驾驶也不容易累,而且它的悬挂调校在保证支撑性的同时也兼顾了日常行驶的舒适性。
Score: 0.5643 Doc 5: 宝马X1的油耗表现相当经济,百公里综合油耗仅为7升左右。
Score: 0.4160 Doc 4: 你知道X1哥吗?好像是个少爷
==================================================
Qwen3-Reranker-0.6B 重排结果
==================================================
Score: 0.7383 Doc 2: 上周末我开着新提的X1跑了一趟长途。动力方面1.5T在市区绝对够用,但上了高速后段加速会有点乏力。不过让我惊喜的是,即便时速超过120公里,车内的风噪和胎噪控制得相当不错,比我预想中要安静很多,这得益于前排的双层夹胶玻璃。
Score: 0.7297 Doc 5: 宝马X1的油耗表现相当经济,百公里综合油耗仅为7升左右。
Score: 0.7122 Doc 1: 关于新款宝马X1的隔音效果,尤其是在高速行驶时怎么样,这是很多车主都非常关心的一个问题,也是衡量车辆高级感的重要指标。
Score: 0.5757 Doc 3: 新款宝马X1的座椅舒适度做得很好,长途驾驶也不容易累,而且它的悬挂调校在保证支撑性的同时也兼顾了日常行驶的舒适性。
Score: 0.5322 Doc 4: 你知道X1哥吗?好像是个少爷很明显,那个正确的废话的相关度很高,某种意义上来说,并没有错,但是和我们的预期是不符的。而reranking之后,我们想要的答案权重高了。
更进一步观察,我们可以发现两个模型对“相关性”的理解层次有所不同。双编码器(bge)将与查询关键词高度重叠的Doc 1排在第一,这是一种高效但相对表层的词法与语义相似性判断。而交叉编码器(reranker)仅识别出Doc 2是最佳答案,还将描述具体评测维度(如油耗)的Doc 5排在了高位,高于关键词重合度更高的Doc 1。
可以说是暗示了交叉编码器其实是具备更强的推理能力:它理解用户的意图是寻求“车辆评测信息”,因此赋予了包含具体用户体验(Doc 2)和客观性能指标(Doc 5)的文档更高的权重,而降低了纯粹复述问题的“正确的废话”(Doc 1)的优先级。这正是重排阶段“慢而精”的价值所在。
7 结语
其实Embedding本身不复杂, 像混合检索、使用标签和元数据大家都已经在应用了。这篇文章从实用角度来说,其实没说什么新东西。
更多的出发点还是动机,说明白embedding layer也好embedding model也好,到底在干什么。真正的去理解embedding是什么,在transformer架构中的作用。
再比如reranking部分其实没必要说这么多,不过我还是想说明从理论角度出发,很多解决方案的诞生是有迹可循的。理论在指导实践,而反过来说,很多工程上的产物又像是实验一样,为理论和假设做出补充。
当然,这里还有很多相关理论的东西没说,比如各向异性(Anisotropy),又或者流形的曲率的影响。这些,等以后深入学习研究了再有机会说说。
8 参考
- GeeksforGeeks. (n.d.). What is Embedding Layer? Retrieved July 29, 2025, from https://www.geeksforgeeks.org/deep-learning/what-is-embedding-layer/
- Deep Lizard. (n.d.). Word Embedding and Word2Vec [Video]. YouTube. Retrieved July 29, 2025, from https://www.youtube.com/watch?v=wgfSDrqYMJ4&t=234s
- StatQuest with Josh Starmer. (n.d.). Word Embedding [Video]. YouTube. Retrieved July 29, 2025, from https://www.youtube.com/watch?v=e6kcs9Uj_ps
- Whitney embedding theorem. (n.d.). In Wikipedia. Retrieved July 29, 2025, from https://en.wikipedia.org/wiki/Whitney_embedding_theorem
- Jakubowski, A., Gasic, M., & Zibrowius, M. (2020). Topology of Word Embeddings: Singularities Reflect Polysemy. In I. Gurevych, M. Apidianaki, & M. Faruqui (Eds.), Proceedings of the Ninth Joint Conference on Lexical and Computational Semantics (pp. 103-113). Association for Computational Linguistics. https://aclanthology.org/2020.starsem-1.11/
- Scikit-learn. (n.d.). 流形学习, from https://scikit-learn.org.cn/view/107.html
- Needham, T. (2021). Visual differential geometry and forms: A mathematical drama in five acts. Princeton University Press.
- Bronstein, M. M., Bruna, J., Cohen, T., & Veličković, P. (n.d.). Geometric deep learning. Retrieved July 29, 2025, from https://geometricdeeplearning.com/
- Wang, Y., Liu, Y., & Sun, M. (2021). A comprehensive study on word embeddings. arXiv. https://arxiv.org/abs/2104.13478
- Cloudflare. (n.d.). What are embeddings? Retrieved July 29, 2025, from https://www.cloudflare.com/zh-cn/learning/ai/what-are-embeddings/
- Volcengine Developer. (n.d.). 向量数据库技术解析. Retrieved July 29, 2025, from https://developer.volcengine.com/articles/7382252634226294794
- LlamaIndex. (n.d.). Semantic chunking. Retrieved July 29, 2025, from https://docs.llamaindex.ai/en/stable/examples/node_parsers/semantic_chunking/
- Verma, J. (2023, December 15). Semantic chunking for RAG. The AI Forum. Retrieved July 29, 2025, from https://medium.com/the-ai-forum/semantic-chunking-for-rag-f4733025d5f5
- LangChain. (n.d.). BM25 retriever. Retrieved July 29, 2025, from https://python.langchain.com/docs/integrations/retrievers/bm25/
- Elastic. (n.d.). Practical BM25 - Part 2: The BM25 algorithm and its variables. Retrieved July 29, 2025, from https://www.elastic.co/blog/practical-bm25-part-2-the-bm25-algorithm-and-its-variables
- Milvus. (n.d.). Metadata filtering with Milvus. Retrieved July 29, 2025, from https://milvus.io/docs/zh/llamaindex_milvus_metadata_filter.md
- Verma, J. (2023, November 20). LLM-based cross-encoder for recommendation. Substack. Retrieved July 29, 2025, from https://januverma.substack.com/p/llm-based-cross-encoder-for-recommendation
- Linzen, T. (2016). Issues in evaluating semantic spaces using word analogies (No. arXiv:1606.07736). arXiv. https://doi.org/10.48550/arXiv.1606.07736
- Nickel, M., & Kiela, D. (2017). Poincaré Embeddings for Learning Hierarchical Representations (No. arXiv:1705.08039). arXiv. https://doi.org/10.48550/arXiv.1705.08039