概念
最长上下文是指模型能够同时考虑的最大token序列长度,包括输入文本和生成文本的总和。
在哪能找到最长上下文
huggingface模型config.json中的max_position_embbedings。从名称上看最长的位置编码嵌入,并不是最长上下文。但是位置编码决定了模型的注意力机制的最大长度,变相限制了模型具备高质量输出的最长上下文。
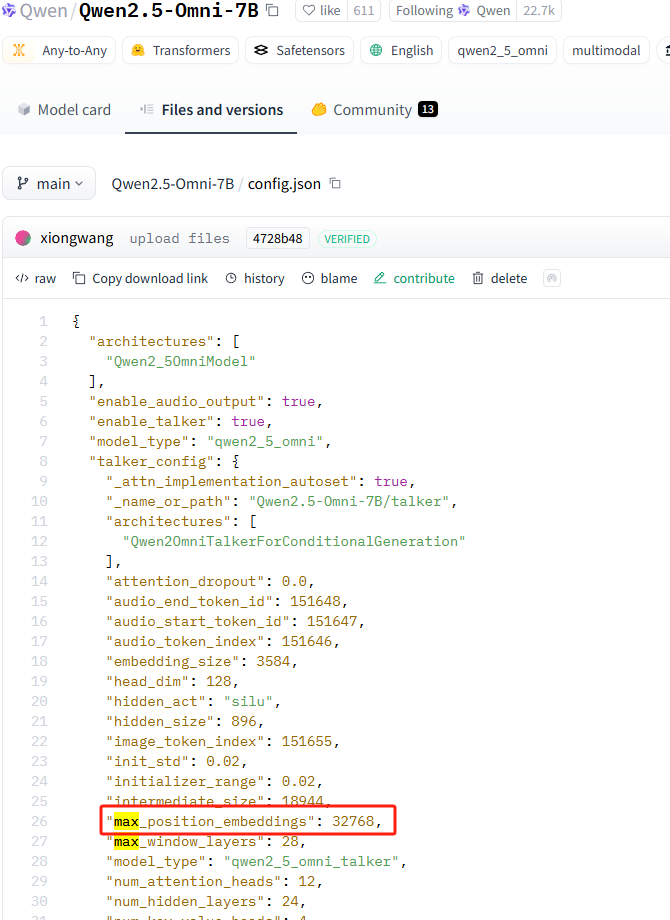
为什么要知道最长上下文?
训练框架如unsloth在加载模型时需要选择,可以更好的分片。(你训练内容长度你不知道么?)
推理框架如vllm支持设置,从而在显存不够时,能更好的控制输入输出内容长度。
那我超过这个长度会如何?
- 不同场景会有不会的方式,但是最常规的做法就是从历史对话的开头开始截断。这就导致:
- 丢失了system prompt
- 失去了对轮对话的能力
- 但是不同的框架去加载,他们各自有各自的策略
- vLLM:一般会设置
max_new_tokens或者max_model_len,其目的是内存分块上的效率优化。但是在这里的效果就是,超出的内容不生成了。以上方模型的32768最大长度为例,我输入32000个input,那么output最多也就768个。 - llama.cpp:Llama.cpp有一个
n_keep参数,可以在超过其处理上限的时候,保留n个token的内容以保证system prompt生效
- vLLM:一般会设置
如何看截断的效果
其中一种方式,我们可以通过查看模型输出的logprob来看。
什么是logprob
- 所以
越接近0,则置信度越高
如何获得logprob
获取logprob
from vllm import LLM, SamplingParams
import pickle
model_name = "Qwen/Qwen2.5-7B-Instruct"
llm = LLM(model=model_name)
sampling_params = SamplingParams(
max_tokens=100,
logprobs=5,
temperature=0.9,
top_p=0.9,
top_k=5,
)
prompt = "Hello, how are you?"
result = llm.generate(prompt, sampling_params)
# 直接保存logprobs对象
with open("logprobs.pkl", "wb") as f:
pickle.dump(result[0].outputs[0].logprobs, f)
# 打印看看内容
print(result[0].outputs[0].logprobs)结果
[{2980: Logprob(logprob=-2.020502805709839, rank=2, decoded_token=' Can'),
358: Logprob(logprob=-0.14224213361740112, rank=1, decoded_token=' I'),
2: Logprob(logprob=-inf, rank=3, decoded_token='#'),
1: Logprob(logprob=-inf, rank=4, decoded_token='"'),
0: Logprob(logprob=-inf, rank=5, decoded_token='!')},
{498: Logprob(logprob=0.0, rank=1, decoded_token=' you'),
2: Logprob(logprob=-inf, rank=2, decoded_token='#'),
0: Logprob(logprob=-inf, rank=3, decoded_token='!'),
3: Logprob(logprob=-inf, rank=4, decoded_token='$'),
1: Logprob(logprob=-inf, rank=5, decoded_token='"')},
{1492: Logprob(logprob=-1.1682757139205933, rank=3, decoded_token=' help'),
4486: Logprob(logprob=-1.1682757139205933, rank=1, decoded_token=' please'),
3291: Logprob(logprob=-1.1682757139205933, rank=2, decoded_token=' tell'),
3410: Logprob(logprob=-2.698709487915039, rank=4, decoded_token=' provide'),
0: Logprob(logprob=-inf, rank=5, decoded_token='!')},
...]这里每个json对象的数字就是token id,decode以后知道其实际含义。logprob是概率,rank是排序。当logprob为-inf的时候,则完全不可能选择。
QUESTION
从这样的结果我们能看出什么?
从logprob找低质量生成
for i, pos in enumerate(logprobs):
top1 = next(v for v in pos.values() if v.rank == 1)
if top1.logprob < -3.0:
print(f"低质量生成位置 {i}: token='{top1.decoded_token}', logprob={top1.logprob}")logprob的断崖式下跌
def detect_truncation(logprobs, threshold=-10.0, drop_threshold=5.0):
truncation_points = []
# 检查logprob绝对值阈值
for i, pos in enumerate(logprobs):
top1 = next(v for v in pos.values() if v.rank == 1)
if top1.logprob <= threshold:
truncation_points.append(i)
# 检查logprob断崖下跌
for i in range(1, len(logprobs)):
prev = next(v for v in logprobs[i-1].values() if v.rank == 1).logprob
curr = next(v for v in logprobs[i].values() if v.rank == 1).logprob
if curr < prev - drop_threshold:
truncation_points.append(i)
return sorted(set(truncation_points))
# 使用示例
trunc_indices = detect_truncation(output[0].outputs[0].logprobs)
if trunc_indices:
print(f"截断可能发生在以下位置: {trunc_indices}")
for i in trunc_indices:
token = next(v for v in output[0].outputs[0].logprobs[i].values() if v.rank == 1).decoded_token
print(f"位置 {i}: token='{token}'")
else:
print("未检测到明显截断")不同框架下与最长上下文相关的参数
vLLM
max_model_len:这个参数定义了模型可以处理的最大序列长度,也就是上下文窗口的大小。它包含了输入提示(prompt)的token数和生成的token数的总和。这个值受模型架构限制,例如对于某些模型可能是4096或8192等。vllm serve "Qwen/QwQ-32B-AWQ" --port 9999 --host 0.0.0.0 --max-model-len 4096
max_new_token&generation-config:可以控制输出的长度。当然,上下文的总长度还是不变的。 image.png
image.png
llama.cpp

n_keep
n_keep是llama.cpp中用于管理上下文窗口截断的重要参数,它定义了当上下文窗口填满时,应该从开始位置保留的token数量。
功能: 当生成过程中上下文长度接近
n_ctx(最大上下文大小)时,llama.cpp会丢弃部分中间内容,但会保留前n_keep个token。应用场景: 通常用于保留系统提示(system prompt)或重要上下文信息,确保这些内容不会在长对话中被截断。
在API中的设置:
struct llama_context_params params = llama_context_default_params(); params.n_keep = 64; // 保留前64个token不会被截断在命令行中:
./main -m model.gguf --keep 64
没有设置n_keep时,当上下文窗口填满,新内容会覆盖最早的内容,可能导致重要的初始提示丢失。
n_tokens
n_tokens表示当前序列中的token总数。它反映了在特定处理阶段模型正在处理的token数量。
- 在日志中可以看到不同阶段的值变化:从2048变为1161
- 这个值会随着处理进行而变化,特别是在进行上下文管理操作后
n_past
n_past表示已经处理过的token数量。它标识了模型在当前上下文窗口中已经看到并处理的token位置。
- 在KV缓存中,从0到
n_past-1的位置存储了已处理token的键值对 - 新生成的token会被放置在
n_past位置 - 这个值会随着生成和处理的进行而增加,如日志中从2048增加到3209
上下文槽位管理 (Context Slot Management)
可以类比理解为的transformers中的max_position_embeddings
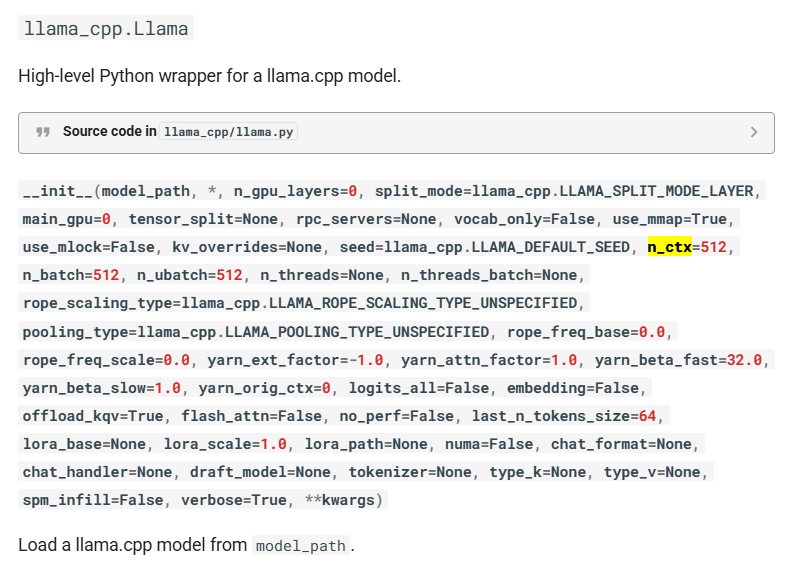
虽然llama.cpp中没有直接名为n_ctx_slot的参数,但它确实实现了上下文槽位管理机制:
KV缓存槽位: llama.cpp使用Key-Value缓存来存储注意力机制的中间结果,每个token对应一个"槽位"。更准确的说每个token对应
个槽位,也就是K和V各一个。所以总槽位数量是 记忆槽管理: 在最新版本的llama.cpp中,实现了更复杂的上下文管理机制:
- sequence_id: 允许在同一上下文中管理多个序列
- logits_all: 控制是否为所有token计算logits或仅最后一个
上下文回收机制: 当使用
llama_kv_cache_seq_rm函数时,可以移除特定序列ID的token,释放上下文槽位供新token使用。llama_kv_cache_seq_rm(ctx, seq_id, p0, p1); // 移除序列中从p0到p1的tokenllama_kv_cache_seq_shift:移动序列位置llama_kv_cache_seq_cp:复制序列内容
槽位重用: llama.cpp实现了一种机制,可以在不复制KV缓存的情况下重用槽位,这对于交互式生成特别有用。
KV cache rm
KV cache rm [start, end]: 表示从KV缓存中移除从start到end范围内的token信息
unsloth
主要长度相关参数
当使用Unsloth初始化或训练模型时,以下参数用于控制最大长度:
max_seq_length: 在创建Unsloth模型时设置的最大序列长度参数,控制训练过程中的上下文窗口大小。
```
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="mistralai/Mistral-7B-v0.1",
max_seq_length=2048, # 设置最大序列长度为2048
dtype=None,
load_in_4bit=True
)
```
内存优化机制
Unsloth的一个主要优势是其内存优化,这与token长度限制密切相关:
- Unsloth实现了FlashAttention-2和其他优化,允许在相同内存条件下处理更长的序列
- 通过分块计算机制减少内存使用,使得能够处理更长的上下文
- 使用梯度检查点(gradient checkpointing)优化,在保持长序列训练能力的同时减少内存占用
参考
vLLM Team. (2025). Engine Arguments — vLLM. Retrieved March 28, 2025, from https://docs.vllm.ai/en/latest/serving/engine_args.html
LangChain. (n.d.). VLLM — 🦜🔗 LangChain documentation. Retrieved from https://python.langchain.com/v0.2/api_reference/community/llms/langchain_community.llms.vllm.VLLM.html
llama-cpp-python. (n.d.). API Reference - llama-cpp-python. Retrieved from https://llama-cpp-python.readthedocs.io/en/latest/api-reference/#llama_cpp.Llama.create_chat_completion
[[原理]] [[心得体会]] [[使用llama.cpp运行qwq-32B做信息抽取]] [[vllm、量化、llama.cpp等]