
加载中...
通过下游任务理解BERT和GPT的区别:不只是完形填空和词语接龙1 写在前面 好久没更新,非常对不住打赏的佬们。本来想写一个大一点的内容,不过还是低估了内容的丰富和复杂度,一直在修修改改。先开个小坑过度一下吧。 2 TL;DL 很多人接触AI,都是直接从GPT开始的。对于一些传统的模型任务和理解不够深入,所以这次要从从最初要解决的任务出发,经过下游任务设计、预训...
加载中...

为什么Embedding加上位置编码后不会破坏语义?1 引言 终于可以说说位置编码了。Tranformer这个结构都说attention很重要,其实另一个非常精彩的设计就是位置编码。现在大多的模型都采用RoPE(Rotary Position Embedding),但这并不意味着最早的正余弦位置编码(有时候也被称为绝对位置编码)就没得可讲了。 所以这...
加载中...
流形视角下的Embedding:从理论到RAG实践1 TL,DR; 把embedding放在基础原理靠后的地方,其实是我写这个系列一开始就想好的。毕竟有了其他模块的一些前置知识以后,可能才会对这些抽象、晦涩的东西感兴趣。 在这部分,我会说一下embedding的的概念,通过流形(Manifold)去从理论角度理解embedding layer,再通...
加载中...
LLM原理
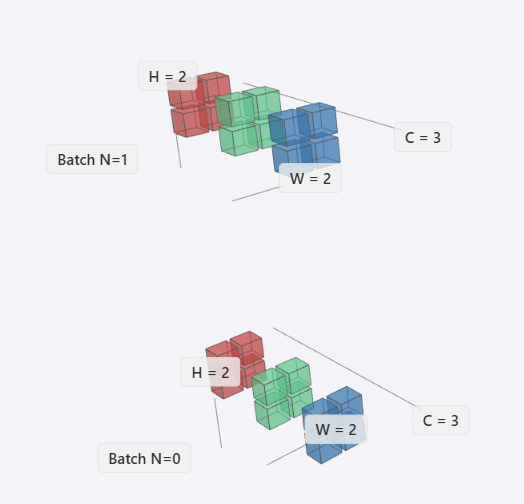
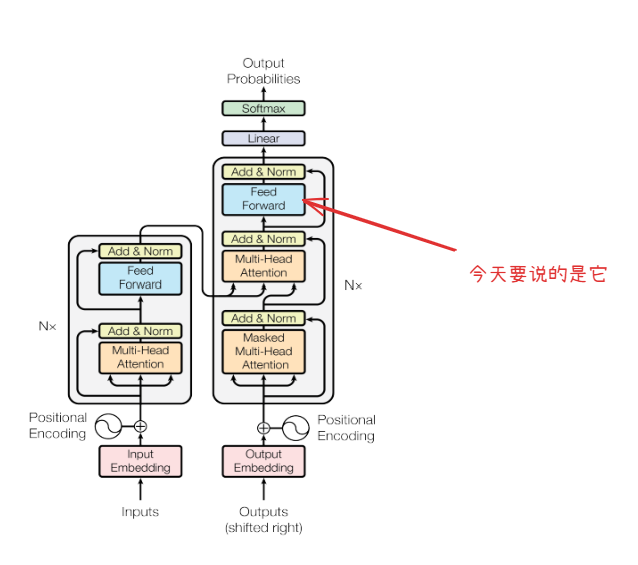
Add & Norm(二):从传统CV到Transformer里的Normalizaiton详解1 写在前面 这一篇会稍微有点偏,我们要说明白Transformer中的LayerNorm和RMSNorm,需要把不同领域的Normalizaiton都过一遍。所以整个文章会从传统的CV领域的CNN开始说明,涉及不同数据样式、作用域和任务目标,最终说明Transformer中的LayerNorm和R...加载中...
LLM原理
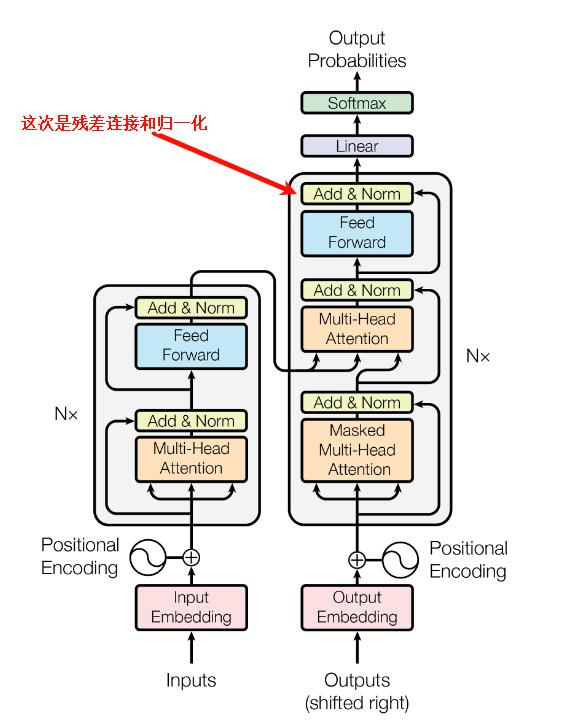
Add & Norm:对残差连接深入解析(一)写在前面 在我最早学习LLMs时候,残差连接这个词看着就很高大上,让我望而生畏,极大的延缓了我系统的学习的进度。但是,因为这样那样的原因,最终我还是恶补了各种知识。学完之后觉得也就那样了,所以,我希望初学者看到tranformer里藏着这样一个部分的时候,可以不用过多担心,直接开始看。 Add & ...加载中...
LLM原理
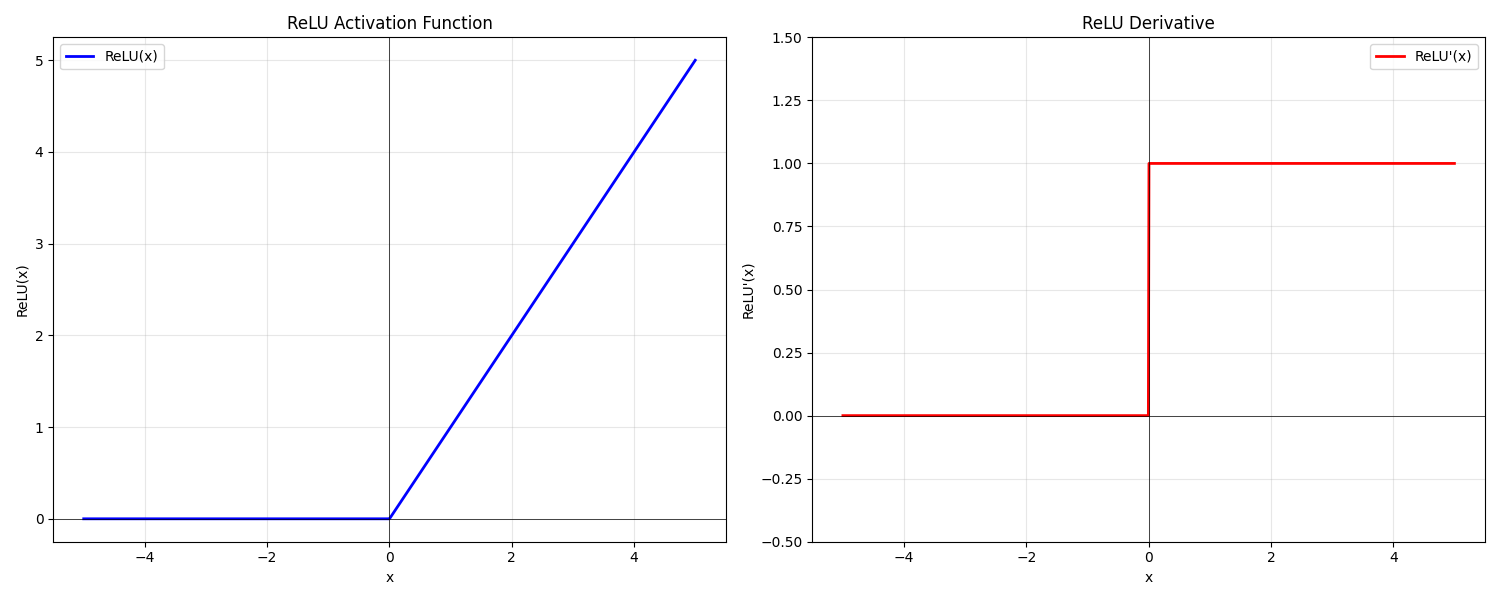
前馈神经网络(FFN)详解(二):从激活函数到MOE1 前言 时隔两周未更新,未曾预料此文篇幅如此之长,其间反复推敲修改多次。主要是不想让读者死背结论,而是希望能切实地从最初的设计理念出发,沿着优化过程中涌现的关键问题,来审视近年来激活函数以及大模型中FFN结构的演变。 因为激活函数处在一种微妙的境地:表面看,如 ReLU 般形态简单、计算高效,其设...加载中...
LLM原理
前馈神经网络(FFN)详解(一)1 前言 FFN,也就是前馈神经网络(Feed-Forward Network)是一个相对简单的结构,原版的论文(attention is all you need)里这块描述的比较简洁,直接进入了更深入的部分,虽然叫”attention is all you need" 但是FFN同样重要。对于F...加载中...
LLM原理
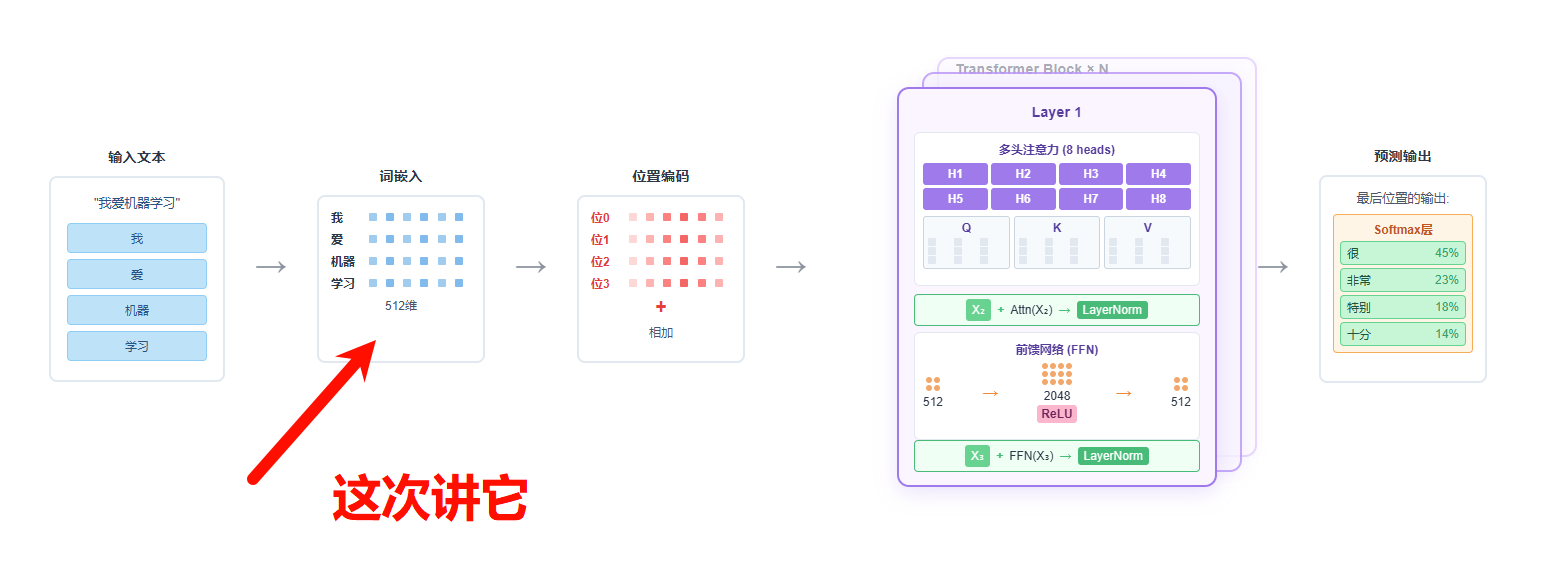
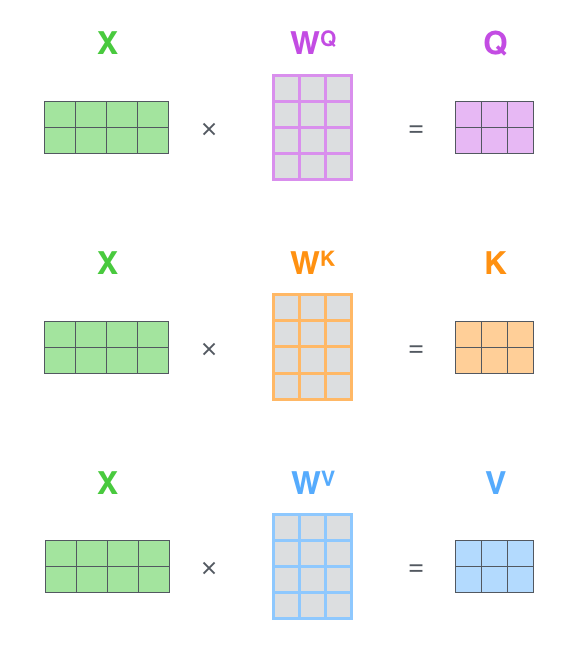
注意力机制之多头注意力(Multi-Head Attention)写在前面 如果对注意力机制本身不太理解的,建议先看。然后再来看这篇。 注意力机制 首先简单回顾一下transformer的流程。我们有一句话我是秦始皇。这个内容会首先进行token分词,然后映射为token id,接着我们会对token_id进行词嵌入,得到然后加入位置编码,得到X。整个步骤如下: ...1
2
3
下页